
Working from home changes everything
When the world started working from home in mid-March 2020, we noticed substantial and sustained changes to our customer’s usage patterns.

Our performance metrics demonstrated these drastic changes. By the end of March, load times were 20-30% slower across the board, even more anomalous than Christmas and New Years Day. After spending time analyzing the data, I verified that we did not release bad code, and instead the severe change resulted from environmental factors. For example, more customers using congested residential networks vs. the faster internet available in offices.
In response to this dramatic shift in demand, Lucid moved quickly to release Lucidspark. This post dives into a small part of that larger effort and how our team worked to improve collaboration performance.
Performance problems while collaborating
To be blunt, in the past our product’s collaboration performance was nothing to brag about. While they’ve always supported collaboration, it was only a great experience with less than 5-8 collaborators actively editing content. At the beginning of summer, we set a goal to reach 30-50 active collaborators, and ended up being able to support 100+ users just in time for the Lucidspark launch.
(We’re still trying to improve this number, check here for the latest guidelines.)
How collaboration works
Letting multiple people collaborate on the same document in a high latency environment (such as over the Internet) is a classic, yet surprisingly complex, computer science problem. Lucid uses a form of Operational Transformation.
TLDR:
Let’s imagine a scenario where Alice and Bob are both typing at the same time.
If Alice and Bob both save their work, the server can only accept one of these saves. If the server accepts Alice’s change, then Bob’s change is rejected for being too old. Bob’s computer must first apply Alice’s change and then Bob’s computer must go back and add in his changes before saving again.

How collaboration broke down
Imagine what would happen if Alice and Bob continued typing, each generating a steady stream of changes. Sometimes Alice’s changes would get in first, other times Bob’s. It’d probably work well enough and they’d be able to effectively collaborate together in real time.
But what if Alice had a substantially faster internet connection? In the time it takes Bob’s computer to receive the rejection, transform his change, and try again, Alice will have saved again and Bob’s edits will continuously get rejected. This causes a negative feedback loop where Bob’s computer needs to transform more and more local changes per failed save, slowing down his save rate and decreasing the probability his saves are accepted by the server.

Now imagine if you add more than two collaborators. In a perfect world, every save would have an equal 1/N chance of being accepted. But the world isn’t perfect, and because of this many collaborators would struggle to save their changes, just like Bob.
Even in a perfect world, this approach doesn’t scale. If 50 people sent a single save request at the same time, only one would be accepted and there would be 49 resaves… then 48… leading to a total of ~1250 requests would be sent before everyone could save once.
Add in if there was an average network latency of 200ms per save attempt, it would take ~10 seconds until the last save was accepted.
Defining success
It’s clear that the naive approach described above will not facilitate large scale collaboration successfully. But before we can try to solve the problem, it’s important to determine what success means.
For Lucid, that very loosely meant, everyone should be able to save quickly. We ended up defining success as, “Every collaborator can see all other collaborator’s changes within X seconds.”
Quick wins
This project was slated for our team from Q1 through Q3. (Luckily, we had a head start.) But like many during 2020, once the pandemic hit, we were still months away from releasing the needed improvements.
Conflict backoff
We implemented a backoff feature to make saving fair across collaborators. If a save was rejected the user’s computer would broadcast to other collaborators, and they would slow down their saving rate. This approach is a form of control theory – an attempt to dynamically equalize the odds of successful saving. Adding in the backoff feature provided modest improvements to the experience, mostly preventing collaborators from becoming permanently unable to save successfully.
Commuting saves
Most of the time, the order users save in doesn’t matter. If two collaborators are typing into two different shapes, their saves don’t actually conflict with one another and both could technically be accepted. However, the server is “dumb” and must reject the old save anyways. Commuting Saves made the server smart enough to analyze the content of a save and the conflicting changes to determine if it can still accept the save out-of-order.
The Long-term solution
The solution we landed on at Lucid was to create a proxy service between the clients and our otherwise “dumb” storage service. The new proxy service would queue up save requests and process them in the order received, guaranteeing fairness. To avoid rejecting old saves the proxy service needed to share model code with our editor so that it could resolve merge conflicts itself.
This presented our biggest challenge to solving the problem: our TypeScript model code was capable of running inside Node.js, which made that a natural runtime choice for this project. However, Lucid has never had a first-class Node.js service before. It was a huge cross-functional effort to get a new Node.js service up and running efficiently during production (e.g. setting up alerts, logging, monitoring, scaling, etc…). An effort that was well worth it, because everything was ready to go for the Lucidspark launch.
Road blocks
Service name
It turns out that naming things is hard. We spent a month or two or three bouncing around names for the new service before landing on one we liked. Eventually our Chief Architect mandated that I had to put an end to the madness and pick a final name. Being unable to handle that level of responsibility myself, I delegated to an engineer on my team, David, who eventually chose a fantastic name (Model Delegate Service). Thanks David!

Collaboration bugs
As more collaborators are added to a document, more changes need to be combined in many different interleavings ultimately resulting in all collaborators hopefully seeing the same document. Unfortunately, there were many subtle bugs within the merging logic that only appeared when there was enough entropy in the system. It turns out that entropy and debugging are not concepts that jive together. We conducted automated tests with Puppeteer, to understand what happens when every collaborator types into the same shape.
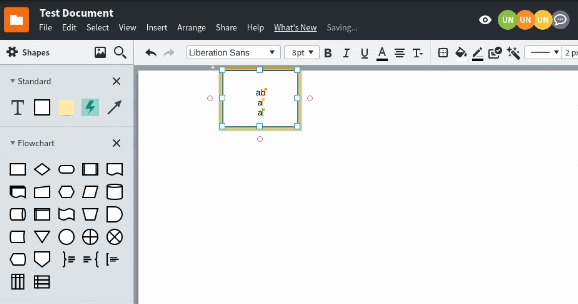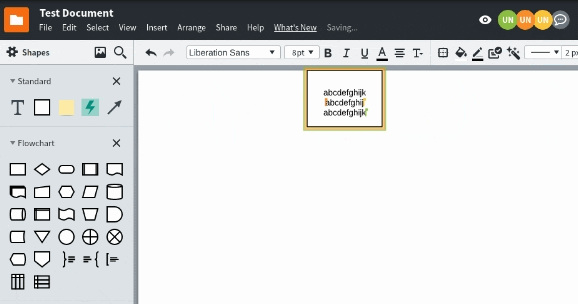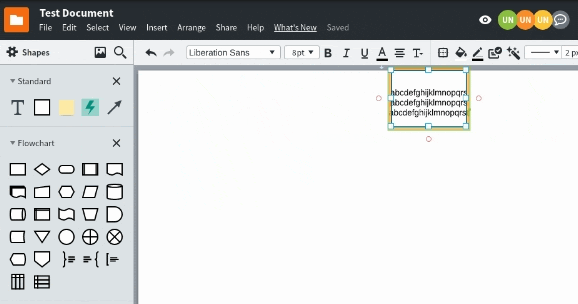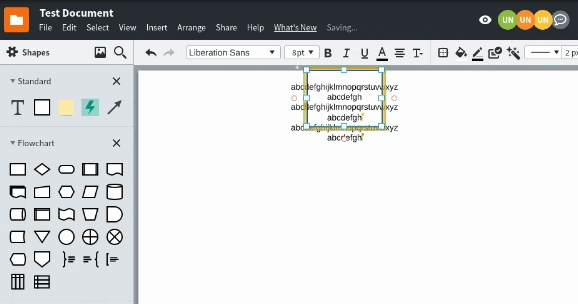
Mob testing
While working on automated testing solutions, nothing beats a good, old-fashion mob test. My team held regularly scheduled mob tests a couple of times a week. In addition, we also held many mob tests involving increasing numbers of employees in our company.
It’s definitely nerve-wracking to purposefully push your new project to fail over and over again in front of many people, including executives. But leaders at Lucid offered support, knowing that this would let us iterate quickly and improve our products.
Success!
Everyone in the organization came together and worked hard throughout the summer so our new service was ready in time for the Lucidspark launch. This experience was an excellent embodiment of one of Lucid’s core values – teamwork over ego. We can now offer our customers a superb large-scale collaboration experience during a time when collaboration is more important than ever.
Interested in solving unique and challenging problems like this? Apply to join our team!

No Comments, Be The First!