Der Datenbank-Designprozess
Eine gut strukturierte Datenbank:
- Reduziert den Speicherplatzbedarf, indem redundante Daten eliminiert werden.
- Wahrt Richtigkeit und Vollständigkeit der Daten.
- Ermöglicht den Zugriff auf die Daten in sinnvoller Weise.
Die Entwicklung einer effizienten, nützlichen Datenbank setzt voraus, dass der ordnungsgemäße Prozess befolgt wird, welcher folgende Aspekte beinhaltet:
- Anforderungsanalyse oder Identifizieren des Zwecks Ihrer Datenbank
- Organisieren von Daten in Tabellen
- Vergeben von Primärschlüsseln und Analysieren von Beziehungen
- Normalisieren zum Standardisieren der Tabellen
Sehen wir uns die einzelnen Schritte genauer an. Bitte beachten Sie, dass dieser Leitfaden Edgar Codds relationales Datenbankmodell, geschrieben in SQL, behandelt (und nicht das hierarchische, Netzwerk- oder Objektdatenmodell). Um mehr über Datenbankmodelle zu erfahren, lesen Sie unseren Leitfaden hier.
Tutorial über die Grundlagen des Datenbankentwurfs in Lucidchart
- Erstellen Sie Ihre erstes Datenbankmodell auf Basis einer Vorlage oder einer leeren Arbeitsfläche.
- Fügen Sie Formen, Linien und Inhalte hinzu, um Ihr Diagramm anzupassen.
- Gestalten und formatieren Sie Ihr Diagramm, damit es zu Ihrem Anwendungsfall passt.
- Verwenden Sie die Funktionssuche in Lucidchart, um zusätzliche Formen und Funktionen zu finden.
- Geben Sie Ihr Datenbankmodell für Ihr Team frei, um Feedback zu erhalten und weiter zu iterieren.
Anforderungsanalyse: Bestimmen des Zwecks der Datenbank
Klarheit über den Zweck Ihrer Datenbank lässt Sie im Laufe des gesamten Designprozesses fundierte Entscheidungen treffen. Denken Sie daran, die Datenbank aus jeder Perspektive zu durchdenken. Wenn Sie beispielsweise eine Datenbank für eine Leihbücherei erstellen, sollten Sie die verschiedenen Arten bedenken, auf die sowohl Besucher als auch Bibliothekare auf die Daten zugreifen können müssen.
Hier sind einige Möglichkeiten, Informationen zu sammeln, bevor Sie die Datenbank erstellen:
- Befragen Sie die Personen, die sie nutzen werden
- Analysieren Sie Geschäftsformulare, wie z. B. Rechnungen, Stundenzettel, Umfragen
- Durchkämmen Sie sämtliche bestehenden Datensysteme (einschließlich physischer und digitaler Akten/Dateien)
Beginnen Sie damit, dass Sie sämtliche bestehenden Daten zusammentragen, die in die Datenbank aufgenommen werden sollen. Listen Sie dann die Arten von Daten auf, die Sie speichern möchten, sowie die Entitäten, oder Personen, Dinge, Orte und Ereignisse, die diese Daten beschreiben, z. B. folgende:
Kunden
- Name
- Adresse
- Stadt, Bundesland, PLZ
- E-Mail-Adresse
Produkte
- Name
- Preis
- Stückzahl auf Lager
- Stückzahl bestellt
Bestellungen
- Auftrags-Nr.
- Vertriebsmitarbeiter
- Datum
- Produkt(e)
- ANZAHL
- Preis
- Insgesamt
Diese Informationen werden später Teil des Datenkatalogs, welcher die Tabellen und Felder innerhalb der Datenbank zusammenfasst. Achten Sie darauf, die Informationen in die kleinsten sinnvollen Einheiten zu zerlegen. Erwägen Sie z. B., die Straße und Hausnummer vom Land zu trennen, sodass Sie später in der Lage sind, Personen nach ihrem Wohnsitzland zu filtern. Vermeiden Sie außerdem, denselben Datenpunkt in mehr als einer Tabelle zu platzieren, was unnötige Komplexität schaffen würde.
Sobald Sie wissen, welche Arten von Daten die Datenbank enthalten wird, woher die Daten kommen und wie sie genutzt werden sollen, sind Sie bereit, mit der Planung der eigentlichen Datenbank zu beginnen.
Datenbank-Struktur: die Grundbausteine einer Datenbank
Der nächste Schritt besteht darin, eine visuelle Darstellung Ihrer Datenbank zu entwerfen. Dazu müssen Sie verstehen, wie genau relationale Datenbanken strukturiert sind.
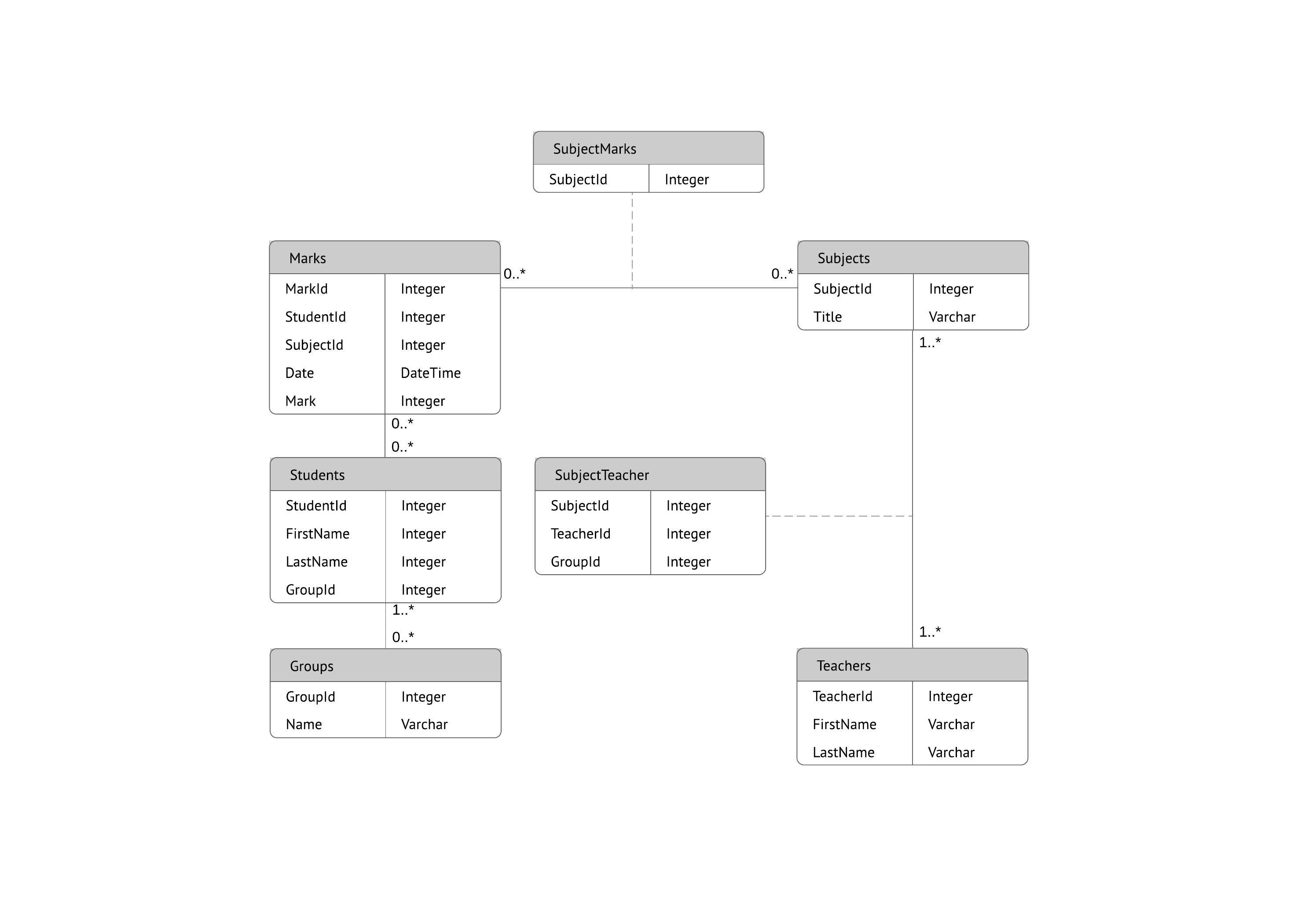
In einer Datenbank werden zusammenhängende Daten in Tabellen gruppiert, von denen jede aus Zeilen (auch Tupel genannt) und Spalten besteht, wie in einer Tabellenkalkulation.
Um Ihre Datenlisten in Tabellen umzuwandeln, beginnen Sie, indem Sie eine Tabelle für jede Art von Entität erstellen, z. B. Produkte, Verkäufe, Kunden und Bestellungen. Hier ist ein Beispiel:
Jede Zeile einer Tabelle wird als Eintrag bezeichnet. Einträge enthalten Daten über etwas oder jemanden, zum Beispiel über einen bestimmten Kunden. Im Gegensatz dazu enthalten Spalten (die auch als Felder oder Attribute bezeichnet werden) eine einzige Information, die in jedem Eintrag auftaucht, so zum Beispiel die Adresse aller in einer Tabelle aufgelisteten Kunden.
| Vorname | Nachname | Alter | Postleitzahl |
|---|---|---|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Damit die Daten von einem Datensatz zum nächsten einheitlich bleiben, weisen Sie jeder Spalte den entsprechenden Datentyp zu. Gebräuchliche Datentypen sind beispielsweise:
- CHAR – eine bestimmte Textlänge
- VARCHAR – Text variabler Länge
- TEXT – große Mengen von Text
- INT – positive oder negative ganze Zahl
- FLOAT, DOUBLE – kann auch Gleitkommazahlen speichern
- BLOB – Binärdaten
Einige Datenbankverwaltungssysteme bieten außerdem den Datentyp AutoNumber an, der automatisch in jeder Zeile eine eindeutige Nummer generiert.
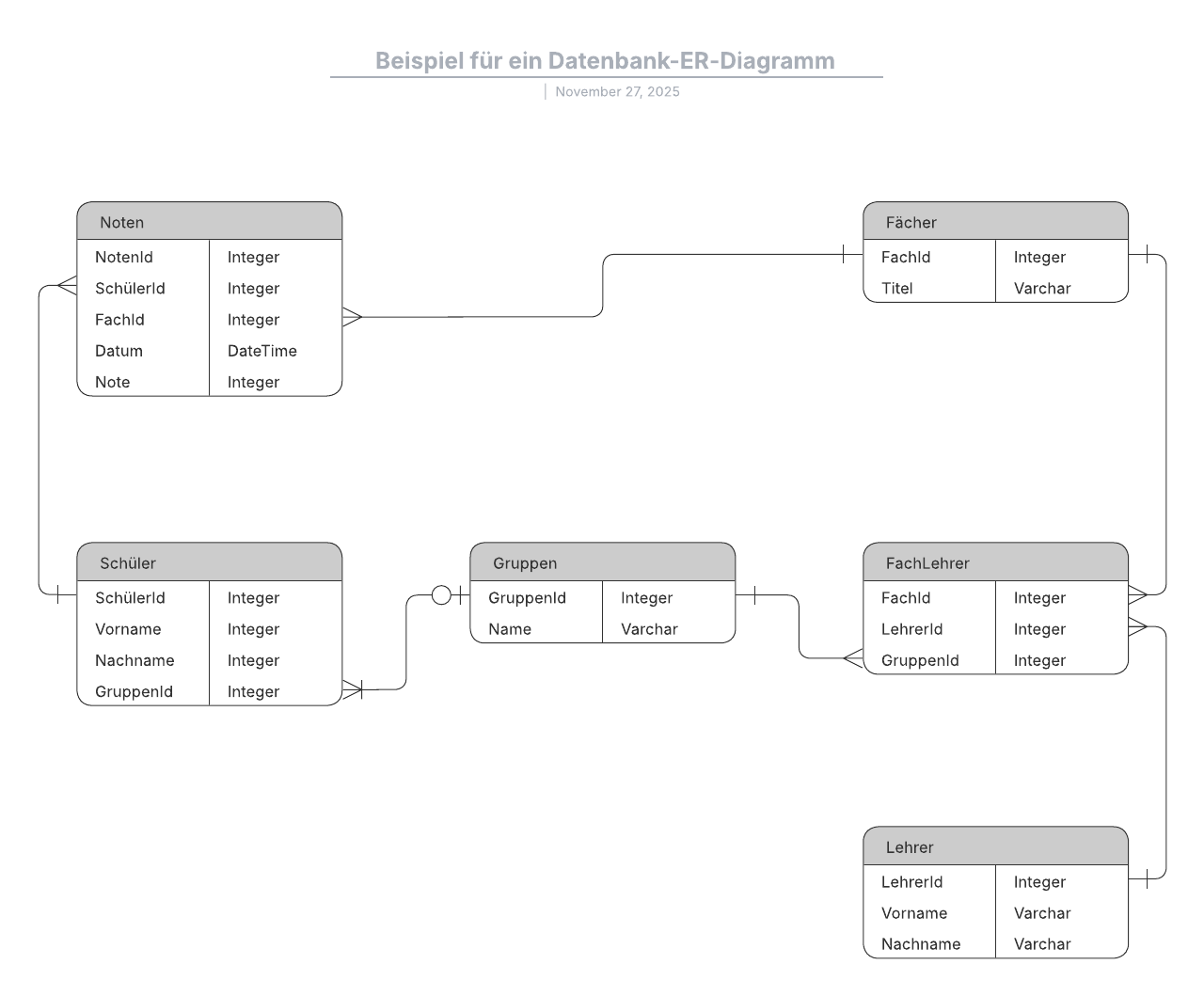
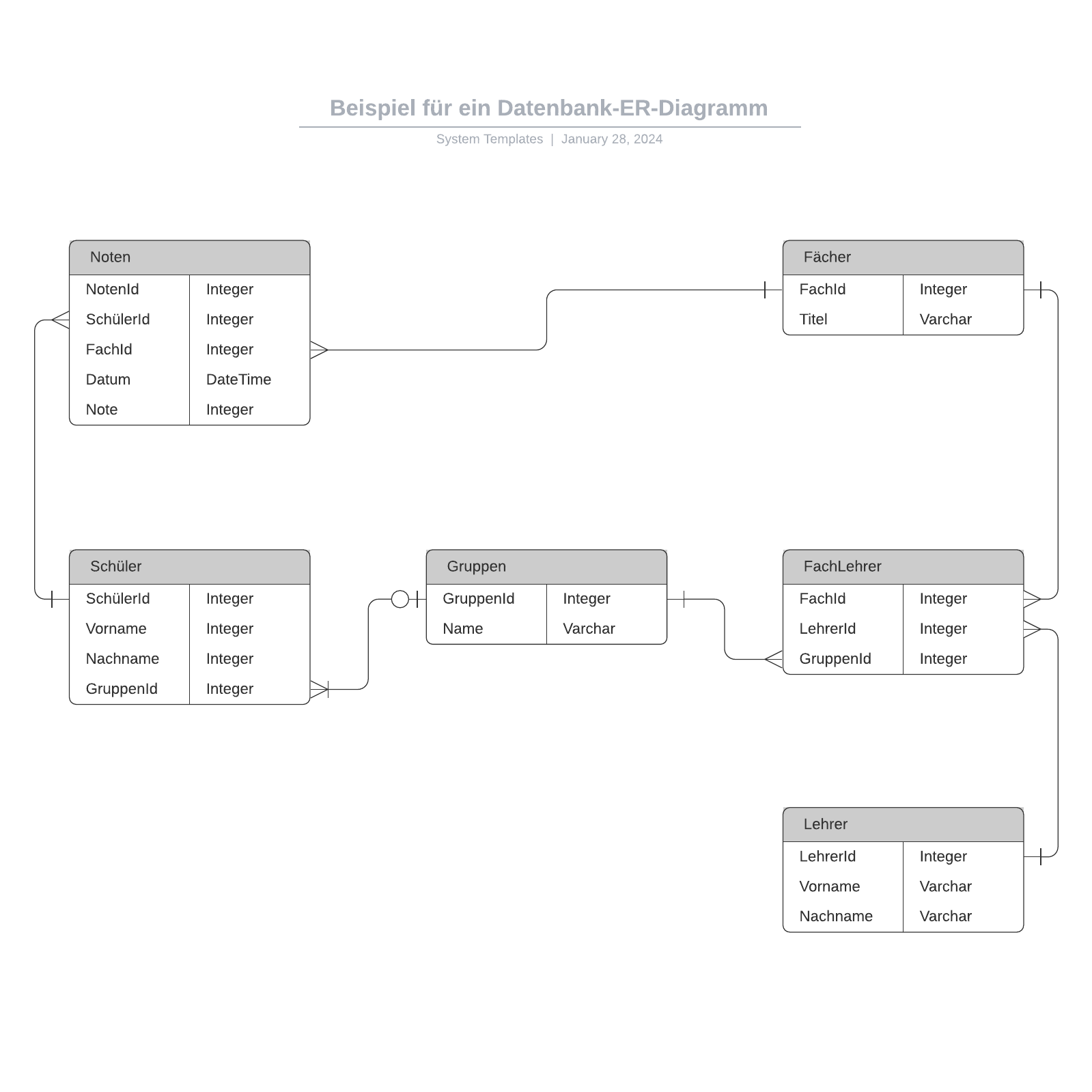
Zum Erstellen einer visuellen Übersicht der Datenbank, bekannt als Entity-Relationship-Diagramm, verwenden Sie nicht die eigentlichen Tabellen. Stattdessen wird jede Tabelle im Diagramm zu einer Box. Der Titel jeder Box sollte angeben, was die Daten in der jeweiligen Tabelle beschreiben, während Attribute darunter aufgelistet werden, wie hier zu sehen:

Schließlich sollten Sie entscheiden, welche(s) Attribut(e) als Primärschlüssel für die jeweiligen Tabellen dienen, falls zutreffend. Ein Primärschlüssel ist eine eindeutige Kennung für eine bestimmte Entität, was heißt, dass Sie einen bestimmten Kunden herausfiltern könnten, selbst wenn Sie nur diesen Wert kennen.
Attribute, die als Primärschlüssel gewählt werden, sollten eindeutig, unverändert und immer vorhanden sein (nie NULL oder leer). Aus diesem Grund eignen Auftragsnummern und Benutzernamen sich gut als Primärschlüssel, Telefonnummern oder Adressen hingegen nicht. Sie können auch mehrere Felder gemeinsam als Primärschlüssel verwenden (dies wird als zusammengesetzter Schlüssel bezeichnet).
Wenn es an der Zeit ist, die eigentliche Datenbank zu erstellen, übertragen Sie sowohl die logische als auch die physische Datenstruktur in die von Ihrem Datenbankverwaltungssystem unterstützte Datendefinitionssprache. An diesem Punkt sollten Sie außerdem die Größe der Datenbank abschätzen, um sicher zu sein, dass Ihnen das Leistungsniveau und der Speicherplatz zur Verfügung stehen, die sie benötigen wird.
Schaffen von Beziehungen zwischen Entitäten
Nun, da Ihre Daten in Tabellen konvertiert sind, sind Sie bereit, die Beziehungen zwischen diesen Tabellen zu analysieren. Kardinalität bezeichnet die Menge an Elementen, die zwischen zwei zusammenhängenden Tabellen interagieren. Das Ermitteln der Kardinalität ist hilfreich, um sicherzustellen, dass Sie die Daten so effizient wie möglich in Tabellen aufgeteilt haben.
Jede Entität kann potenziell eine Beziehung zu jeder anderen haben, aber diese Beziehungen gehören für gewöhnlich einem von drei Typen an:
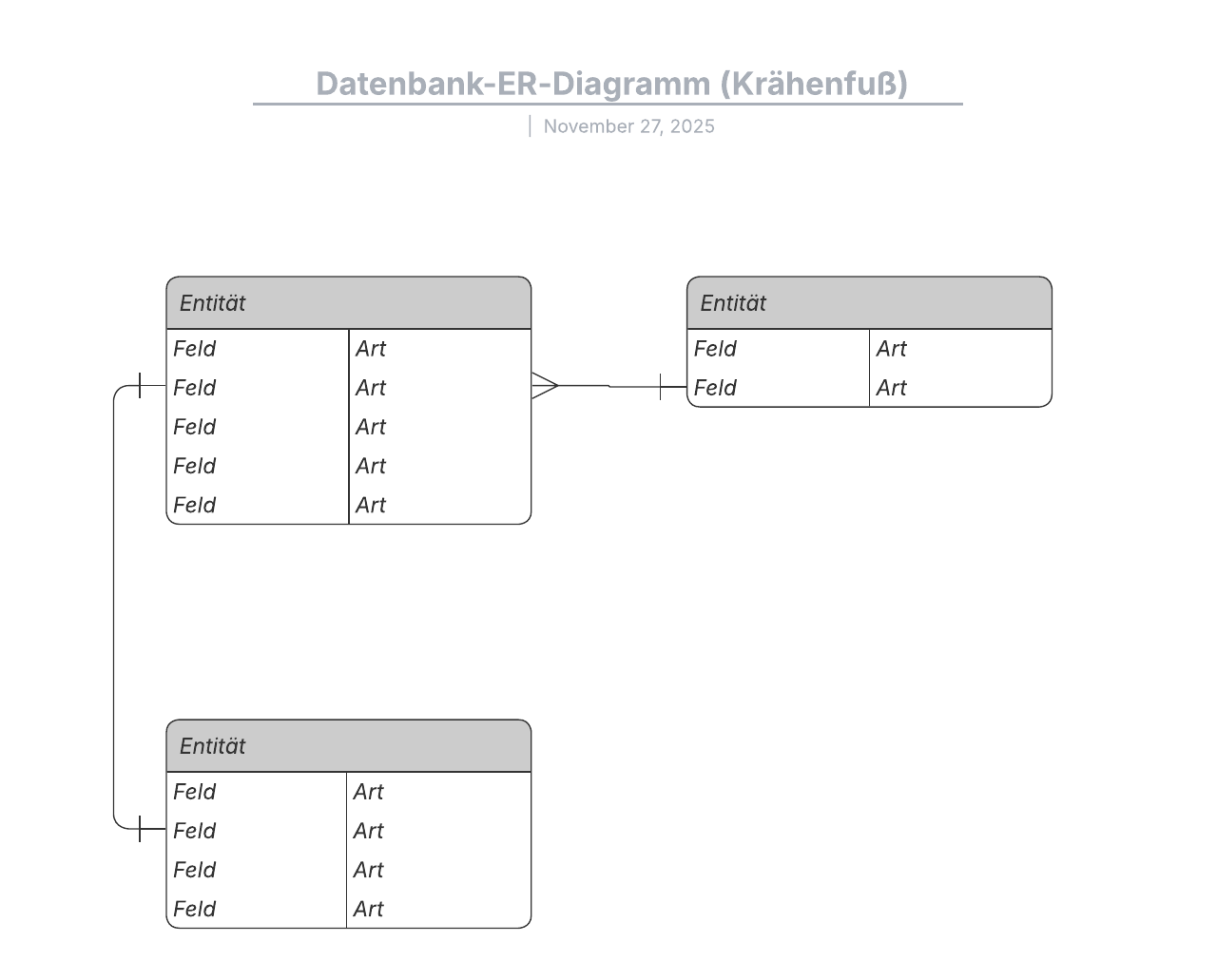
Eins-zu-eins-Beziehungen
Wenn nur eine Instanz von Entität A für jede Instanz von Entität B vorhanden ist, sagt man, dass sie eine Eins-zu-eins-Beziehung (oft 1:1 geschrieben) haben. Sie können diese Art von Beziehung in einem ER-Diagramm mit einer Linie mit einem Strich an beiden Enden darstellen:

Sofern Sie keinen guten Grund haben, dies nicht zu tun, weist eine 1:1-Beziehung meist darauf hin, dass es sinnvoller wäre, wenn Sie die Daten der beiden Tabellen in einer einzigen Tabelle zusammenfassen würden.
Allerdings wollen Sie Tabellen vielleicht unter bestimmten Umständen in einer 1:1-Beziehung erstellen. Wenn Sie ein Feld mit optionalen Daten wie z. B. „Beschreibung“ haben, das für viele Einträge leer ist, können Sie alle Beschreibungen in eine eigene Tabelle verschieben, um so leeren Platz zu beseitigen und die Datenbank-Performance zu verbessern.
Damit die Daten auch korrekt abgeglichen werden, müssen Sie in jeder Tabelle mindestens eine identische Spalte verwenden (wahrscheinlich den Primärschlüssel).
Eins-zu-viele-Beziehungen
Diese Beziehungen treten auf, wenn ein Eintrag in einer Tabelle mit mehreren Einträgen in einer anderen assoziiert ist. Zum Beispiel kann es vorkommen, dass ein Kunde viele Bestellungen aufgibt oder ein Gast mehrere Bücher gleichzeitig aus der Bücherei ausleiht. Eins-zu-viele-Beziehungen (1:m) werden mit einer sogenannten „Krähenfuß-Notation“ angegeben, wie in diesem Beispiel:

Zur Implementierung einer 1:m-Beziehung bei der Einrichtung einer Datenbank müssen Sie einfach nur den Primärschlüssel von der „einen“ Seite der Beziehung als Attribut zu der anderen Tabelle hinzufügen. Wenn ein Primärschlüssel in einer anderen Tabelle auf diese Weise aufgeführt ist, wird er als Fremdschlüssel bezeichnet. Die Tabelle auf der „1“-Seite der Beziehung wird als übergeordnete Tabelle der untergeordneten Tabelle auf der anderen Seite betrachtet.
Viele-zu-viele-Beziehungen
Wenn mehrere Entitäten aus einer Tabelle mit mehreren Entitäten in einer anderen Tabelle assoziiert werden können, ist das eine Viele-zu-viele-Beziehung (n:m). Das kann bei Studenten und Kursen passieren, weil ein Student viele Kurse belegen und ein Kurs viele Studenten aufnehmen kann.
In einem ER-Diagramm werden diese Beziehungen durch folgende Linien gekennzeichnet:

Leider lässt sich diese Art von Beziehung nicht direkt in einer Datenbank implementieren. Stattdessen müssen Sie diese in zwei 1:m-Beziehungen aufspalten.
Dazu müssen Sie eine neue Entität zwischen diesen beiden Tabellen erstellen. Wenn die n:m-Beziehung zwischen Verkäufen und Produkten besteht, können Sie diese Entität zum Beispiel „verkaufte_produkte“ nennen, da sie den Inhalt jedes einzelnen Verkaufs zeigt. Sowohl die Verkäufe- als auch die Produkt-Tabelle hätten dann eine 1:m-Beziehung zu „verkaufte_produkte“. Diese Art der Zwischenentität wird in verschiedenen Modellen als Verknüpfungstabelle, assoziative Entität oder Verbindungstabelle bezeichnet.
Jeder Eintrag in der Verknüpfungstabelle fügt zwei Entitäten in den angrenzenden Tabellen zusammen (und kann auch ergänzende Informationen enthalten). Eine Verknüpfungstabelle zwischen Studenten und Kursen kann zum Beispiel so aussehen:

Pflicht oder Kür?
Eine andere Methode zur Analyse von Beziehungen ist die Überlegung, welche Seite der Beziehung existieren muss, bevor die andere existieren kann. Die optionale Seite kann mit einem Kreis auf der Linie markiert werden, wo sonst ein Freiraum zwischen den Strichen wäre. Es muss zum Beispiel ein Staat existieren, damit dieser einen UN-Vertreter hat. Das Gegenteil ist jedoch nicht der Fall:

Zwei Entitäten können voneinander abhängen (eine kann nicht ohne die andere existieren).
Rekursive Beziehungen
Manchmal verweist eine Tabelle auf sich selbst. Eine Tabelle mit Mitarbeitern kann zum Beispiel das Attribut „Manager“ haben, das auf eine andere Person in derselben Tabelle verweist. Das wird als rekursive Beziehung bezeichnet.
Redundante Beziehungen
Eine redundante Beziehung ist eine Beziehung, die mehr als einmal ausgedrückt wird. Üblicherweise könnten Sie eine der Beziehungen entfernen, ohne wichtige Informationen zu verlieren. Wenn zum Beispiel eine Entität namens „Studenten“ eine direkte Beziehung zu einer anderen Entität namens „Dozenten“ hat, aber auch indirekt eine Beziehung zu den Dozenten durch „Kurse“, sollten Sie die Beziehung zwischen „Studenten“ und „Dozenten“ entfernen. Es ist besser, diese Beziehung zu löschen, weil die Studenten den Dozenten nur über Kurse zugewiesen werden.
Datenbanknormalisierung
Sobald Sie ein vorläufiges Design für Ihre Datenbank haben, können Sie Normalisierungsregeln anwenden, damit die Tabellen korrekt strukturiert werden. Betrachten Sie diese Regeln als Branchenstandards.
Allerdings ist zu bedenken, dass nicht alle Datenbanken für die Normalisierung geeignet sind. Allgemein sollten OLTP-Datenbanken (Online transaction processing, deutsch Online-Transaktionsverarbeitung), in denen Benutzer Einträge erstellen, lesen, aktualisieren und löschen, normalisiert werden.
OLAP-Datenbanken (Online Analytical Processing, Online-Analyseverarbeitung), die sich für Analysen und Berichte eignen, machen mit etwas Denormalisierung vielleicht eine bessere Figur, weil der Fokus auf der Berechnungsgeschwindigkeit liegt. Dazu gehören Anwendungen zur Entscheidungsunterstützung, bei denen Daten zwar schnell analysiert, jedoch nicht geändert werden müssen.
Jede Form oder Stufe der Normalisierung umfasst die Regeln der niedrigeren Formen.
Erste Normalform
Die erste Normalform (als 1NF abgekürzt) gibt an, dass jede Zelle in der Tabelle nur einen Wert und niemals eine Liste mit Werten haben kann. So entspricht die folgende Tabelle nicht den Vorgaben:
| Produkt-ID | Farbe | Preis |
|---|---|---|
| 1 | braun, gelb | 15 $ |
| 2 | rot, grün | 13 $ |
| 3 | blau, orange | 11 $ |
Sie sind vielleicht versucht, das zu umgehen, indem Sie diese Daten in weitere Spalten aufteilen – aber auch das verstößt gegen die Regeln: Eine Tabelle mit Gruppen von sich wiederholenden oder eng verwandten Attributen erfüllt die erste Normalform nicht. Folgende Tabelle entspricht zum Beispiel nicht den Anforderungen:

Stattdessen sollten Sie die Daten in mehrere Tabellen oder Einträge aufteilen, bis jede Zelle nur einen Wert enthält und es keine zusätzlichen Spalten gibt. An diesem Punkt werden die Daten als atomar bezeichnet, d. h. die kleinste nutzbare Größe. Für die obige Tabelle könnten Sie eine weitere Tabelle namens „Verkaufsdetails“ erstellen, die bestimmte Produkte mit Verkäufen zusammenführen könnte. „Verkäufe“ hätte dann eine 1:m-Beziehung zu „Verkaufsdetails“.
Zweite Normalform
Die zweite Normalform (2NF) gibt vor, dass jedes Attribut vollständig vom gesamten Primärschlüssel abhängig sein muss. Das bedeutet, dass jedes Attribut direkt vom Primärschlüssel abhängig sein muss und nicht indirekt durch ein anderes Attribut.
Das Attribut „age“ hängt zum Beispiel von „birthdate“ ab, das wiederum abhängig von „studentID“ ist. Das ist eine sogenannte partielle funktionelle Abhängigkeit und eine Tabelle mit diesen Attributen würde der zweiten Normalform nicht entsprechen.
Außerdem verstößt eine Tabelle mit einem Primärschlüssel aus mehreren Feldern gegen die zweite Normalform, wenn ein oder mehrere der sonstigen Felder nicht von jedem Teil des Schlüssels abhängig sind.
Daher würde eine Tabelle mit diesen Feldern die zweite Normalform nicht erfüllen, denn das Attribut „product name“ hängt von der ProduktID, jedoch nicht von der Bestellnummer ab:
-
Bestellnummer (Primärschlüssel)
-
Produkt-ID (Primärschlüssel)
- Produktname
Dritte Normalform
Die dritte Normalform (3NF) fügt diesen Regeln die Anforderung hinzu, dass jede Spalte außerhalb des Schlüssels von allen anderen Spalten unabhängig sein muss. Wenn die Änderung eines Werts in einer Nicht-Schlüssel-Spalte die Änderung eines anderen Werts bedingt, erfüllt diese Tabelle die dritte Normalform nicht.
Dadurch können Sie keine abgeleiteten Daten wie z. B. die Spalte „Steuern“ im Folgenden in der Tabelle speichern, da diese direkt vom Gesamtpreis der Bestellung abhängig ist:
| Bestellung | Preis | Steuern |
| 14325 | 40,99 $ | 2,05 $ |
| 14326 | 13,73 $ | 0,69 $ |
| 14327 | 24,15 $ | 1,21 $ |
Es wurden weitere Formen der Normalisierung vorgeschlagen, darunter die Normalform nach Boyce und Codd, die vierte bis sechste Normalform und die Domain-Key-Normalform, aber die ersten drei sind die häufigsten.
Obwohl diese Formen die bewährten Methoden erklären, die generell befolgt werden sollten, hängt der Grad der Normalisierung vom Kontext der Datenbank ab.
Multidimensionale Daten
Einige Benutzer möchten vielleicht auf mehrere Dimensionen eines einzigen Datentyps zugreifen, was besonders bei OLAP-Datenbanken der Fall ist. Vielleicht wollen sie die Verkäufe nach Kunde, Bundesstaat und Monat aufschlüsseln. In dieser Situation sollte am besten eine zentrale Tabelle erstellt werden, auf die andere Kunden-, Bundesstaats- und Monatstabellen verweisen können, wie hier gezeigt:

Datenintegritätsregeln
Sie sollten Ihre Datenbank außerdem so konfigurieren, dass die Daten entsprechend den zutreffenden Regeln validiert werden. In vielen Datenbank-Managementsystemen wie Microsoft Access werden einige dieser Regeln automatisch angewendet.
Die Entitäts-Integritätsregel besagt, dass der Primärschlüssel niemals NULL lauten kann. Wenn der Schlüssel aus mehreren Spalten besteht, darf keine von ihnen NULL lauten. Andernfalls kann der Eintrag möglicherweise nicht als einmalig erkannt werden.
Die Verweis-Integritätsregel verlangt, dass jeder Fremdschlüssel in einer Tabelle aufgeführt ist, um gegen einen Primärschlüssel in der verwiesenen Tabelle abgeglichen zu werden. Wenn der Primärschlüssel geändert oder gelöscht wird, müssen diese Änderungen in der gesamten Datenbank überall dort implementiert werden, wo auf diesen Schlüssel verwiesen wird.
Die Geschäftslogik-Integritätsregeln stellen sicher, dass sich die Daten innerhalb bestimmter logischer Parameter bewegen. Ein Termin müsste zeitlich zum Beispiel in die üblichen Öffnungszeiten fallen.
Indizes und Ansichten hinzufügen
Ein Index ist praktisch eine sortierte Kopie einer oder mehrerer Spalten, wobei die Werte entweder aufsteigend oder absteigend sortiert sind. Durch das Hinzufügen eines Indexes finden Benutzer Einträge schneller. Anstatt für jede Abfrage neu sortieren zu müssen, kann das System in der vom Index festgelegten Reihenfolge auf Einträge zugreifen.
Obwohl Indizes den Datenabruf beschleunigen, können Sie das Einfügen, Aktualisieren und Löschen verlangsamen, weil der Index bei jeder Eintragsänderung neu erzeugt werden muss.
Eine Ansicht ist schlicht eine gespeicherte Abfrage zu den Daten. Ansichten können Daten aus mehreren Tabellen auf nützliche Weise zusammenfügen oder einen Teil einer Tabelle zeigen.
Erweiterte Eigenschaften
Sobald Sie das grundlegende Layout abgeschlossen haben, können Sie die Datenbank mit erweiterten Eigenschaften wie Anleitungstexten, Eingabemasken und Formatierungsregeln ausstatten, die für ein(e) bestimmte(s) Schema, Ansicht oder Spalte gelten. Der Vorteil liegt darin, dass die Regeln in der Datenbank selbst gespeichert werden und die Präsentation der Daten somit in den Programmen, die auf die Daten zugreifen, konsistent bleibt.
SQL und UML
Die Unified Modeling Language (UML) ist eine weitere visuelle Möglichkeit, komplexe Systeme, die in einer objektorientierten Sprache erstellt wurden, auszudrücken. Mehrere der in diesem Leitfaden genannten Konzepte sind im Rahmen der UML unter anderen Namen bekannt. Zum Beispiel wird eine Entität in UML als Klasse bezeichnet.
UML wird heute nicht mehr so häufig eingesetzt wie früher. Heute wird sie oft im akademischen Bereich und bei der Kommunikation zwischen Software-Designern und ihren Kunden verwendet.
Datenbank-Management-Systeme
Viele Design-Entscheidungen, die Sie treffen werden, hängen vom verwendeten Datenbank-Managementsystem ab. Einige übliche Systeme sind:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Wenn Sie die Wahl haben, sollten Sie Ihr Managementsystem anhand von Kosten, Betriebssystemunterstützung, Funktionen und weiteren Faktoren auswählen.
Was ist ein Datenbank-Schema?
Ein Datenbankschema steht für die logische Konfiguration einer relationalen Datenbank oder eines Teils davon. Es kann sowohl als anschauliche Darstellung als auch als Integritätseinschränkungen, d. h. als Gruppe von Formeln, denen eine Datenbank unterliegt, dargestellt werden. Diese Formeln werden in einer Datendefinitionssprache wie z. B. SQL ausgedrückt. Als Teil eines Datenlexikons gibt ein Datenbankschema an, in welcher Beziehung die Entitäten wie Tabellen, Ansichten, gespeicherte Abläufe usw., aus denen die Datenbank besteht, zueinander stehen.

Üblicherweise erstellt ein Datenbankdesigner ein Datenbankschema, um Programmierer zu unterstützen, deren Software mit der Datenbank interagieren wird. Der Vorgang der Erstellung eines Datenbankschemas wird Datenmodellierung genannt. In einer Drei-Schema-Architektur für Datenbankdesign würde dieser Schritt der Erstellung eines konzeptionellen Schemas entsprechen. Bei konzeptionellen Schemata stehen die Informationsbedürfnisse eines Unternehmens im Vordergrund, nicht die Struktur einer Datenbank.
Es gibt zwei Hauptarten von Datenbank-Schemata:
- Ein logisches Datenbankschema vermittelt die logischen Einschränkungen, die für die gespeicherten Daten gelten. Es kann Integritätseinschränkungen, Ansichten und Tabellen festlegen.
- Ein physisches Datenbankschema stellt dar, wie die Daten physisch als Dateien und Indizes auf einem Speichersystem gespeichert werden.
Auf der einfachsten Ebene gibt ein Datenbankschema an, aus welchen Tabellen oder Relationen die Datenbank besteht, sowie welche Felder in jeder Tabelle enthalten sind. Folglich sind die Begriffe Schemadiagramm und Entity-Relationship-Diagramm häufig austauschbar.
Schema im Datenbanksystem Oracle
Im Oracle-Datenbanksystem hat der Begriff Datenbankschema oder auch „SQL-Schema“ eine andere Bedeutung. Hier kann eine Datenbank mehrere Schemata haben. In jedem Schema sind alle Objekte enthalten, die von einem bestimmten Nutzer der Datenbank erstellt wurden. Zu diesen Objekten können Tabellen, Ansichten, Synonyme usw. gehören. Manche Objekte wie z. B. Nutzer, Kontexte, Rollen und Verzeichnisobjekte können nicht in ein Schema aufgenommen werden.

Nutzer können die nötigen Zugriffsrechte erhalten, um sich je nach Fall bei einzelnen Schemata einzuloggen, und die Inhaberschaft ist übertragbar. Da jedes Objekt mit einem bestimmten Schema assoziiert ist, das als eine Art Namespace dient, ist die Vergabe einiger Synonyme sinnvoll. Somit können andere Nutzer auf das entsprechende Objekt zugreifen, ohne sich vorher auf das Schema, zu dem es gehört, beziehen zu müssen.
Diese Schemata geben nicht zwingend an, wie die Dateien physisch gespeichert werden. Stattdessen werden Schemaobjekte logisch in einem Tablespace gespeichert. Der Datenbankadministrator kann festlegen, wie viel Platz er einem bestimmten Objekt innerhalb einer Datei zuweisen möchte.
Schemata und Tablespaces stimmen nicht immer vollständig überein: Objekte aus einem Schema können in mehreren Tablespaces zu finden sein und ein Tablespace kann Objekte aus mehreren Schemata enthalten.
Datenbankinstanz oder Datenbankschema?
Diese Begriffe sind zwar verwandt, bedeuten aber nicht dasselbe. Ein Datenbankschema ist eine Skizze einer geplanten Datenbank. Es enthält selbst keine Daten.
Eine Datenbankinstanz wiederum ist eine Momentaufnahme einer Datenbank zu einem bestimmten Zeitpunkt. Datenbankinstanzen können sich also im Laufe der Zeit verändern. Datenbankschemata hingegen sind in der Regel statisch, da sich die Struktur einer Datenbank nur schwer ändern lässt, wenn sie einmal in Betrieb genommen wurde.
Datenbankschemata und Datenbankinstanzen können einander über ein Datenbank-Management-System (DBMS) beeinflussen. Das DBMS sorgt dafür, dass jede Datenbankinstanz die von den Datenbankdesignern im Datenbankschema festgelegten Einschränkungen erfüllt.
Anforderungen für Schema-Integrationen
Es kann sinnvoll sein, mehrere Quellen in einem einzigen Schema zu vereinen. Um einen nahtlosen Übergang zu gewährleisten, sollten Sie darauf achten, dass folgende Anforderungen erfüllt sind:
Bewahrung von Überschneidungen
Jedes sich überschneidende Element in den Schemata, die Sie miteinander integrieren möchten, sollte sich in einer Datenbankschematabelle befinden.
Erweiterte Bewahrung von Überschneidungen
Elemente, die nur in einer Quelle auftauchen, aber mit sich überschneidenden Elementen assoziiert sind, sollten in das neu erzeugte Datenbankschema kopiert werden.
Normalisierung
Unabhängige Beziehungen und Entitäten sollten nicht einfach in die gleiche Tabelle im Datenbankschema geworfen werden.
Minimalität
Idealerweise gehen keine Elemente aus den Quellen verloren.
Arten von Datenbankschemata
Beim Design von Datenbankschemata haben sich einige Muster herauskristallisiert.
Das einfachste Schema ist das weit verbreitete Stern-Schema. Dabei werden eine oder mehrere Faktentabellen mit einer beliebigen Anzahl dimensionaler Tabellen verbunden. Dieses Schema eignet sich am besten für einfache Abfragen.
Das damit verwandte Schneeflockenschema wird ebenfalls zur Darstellung einer mehrdimensionalen Datenbank verwendet. In diesem Muster werden die Dimensionen jedoch zu Gruppen separater Tabellen normalisiert. So entsteht der Ausbreitungseffekt einer schneeflockenartigen Struktur.