Arten von Datenbankmodellen
Es gibt viele Arten von Datenbankmodellen. Einige der am häufigsten verwendeten sind:
- Hierarchisches Datenbankmodell
- Relationales Modell
- Netzwerkmodell
- Objektorientiertes Datenbankmodell
- Entity-Relationship-Modell
- Dokumentenmodell
- Entität-Attribut-Wert-Modell
- Sternschema
- Das objektrelationale Modell, das die beiden namensgebenden Modell kombiniert
Sie können eine Datenbank mit einem beliebigen dieser Modelle beschreiben, je nach unterschiedlichen Faktoren. Der größte Faktor ist die Unterstützung des Modells durch das von Ihnen verwendete Datenbank-Managementsystem. Die meisten Datenbank-Managementsysteme sind auf bestimmte Datenmodelle ausgelegt und zwingen ihre Benutzer zur Verwendung dieses Modells. Nur einige wenige unterstützen mehrere Modelle.
Außerdem beziehen sich die meisten Modelle auf unterschiedliche Phasen des Design-Prozesses. Grobe, konzeptionelle Datenmodelle eignen sich bestens zur Darstellung von Beziehungen zwischen Daten auf die Weise, in der Menschen diese Daten wahrnehmen. Eintragsbasierte logische Modelle geben dagegen eher die Methode wieder, mit der die Daten auf dem Server gespeichert werden.
Bei der Auswahl eines Datenmodells geht es auch darum, Ihre Prioritäten für die Datenbank mit den Stärken eines bestimmten Modells in Einklang zu bringen. Diese Prioritäten können Geschwindigkeit, Kostensenkung, Benutzerfreundlichkeit und vieles mehr umfassen.
Sehen wir uns die üblichsten Datenbankmodelle einmal genauer an.
Tutorial über die Grundlagen des Datenbankentwurfs in Lucidchart
- Erstellen Sie Ihre erstes Datenbankmodell auf Basis einer Vorlage oder einer leeren Arbeitsfläche.
- Fügen Sie Formen, Linien und Inhalte hinzu, um Ihr Diagramm anzupassen.
- Gestalten und formatieren Sie Ihr Diagramm, damit es zu Ihrem Anwendungsfall passt.
- Verwenden Sie die Funktionssuche in Lucidchart, um zusätzliche Formen und Funktionen zu finden.
- Geben Sie Ihr Datenbankmodell für Ihr Team frei, um Feedback zu erhalten und weiter zu iterieren.
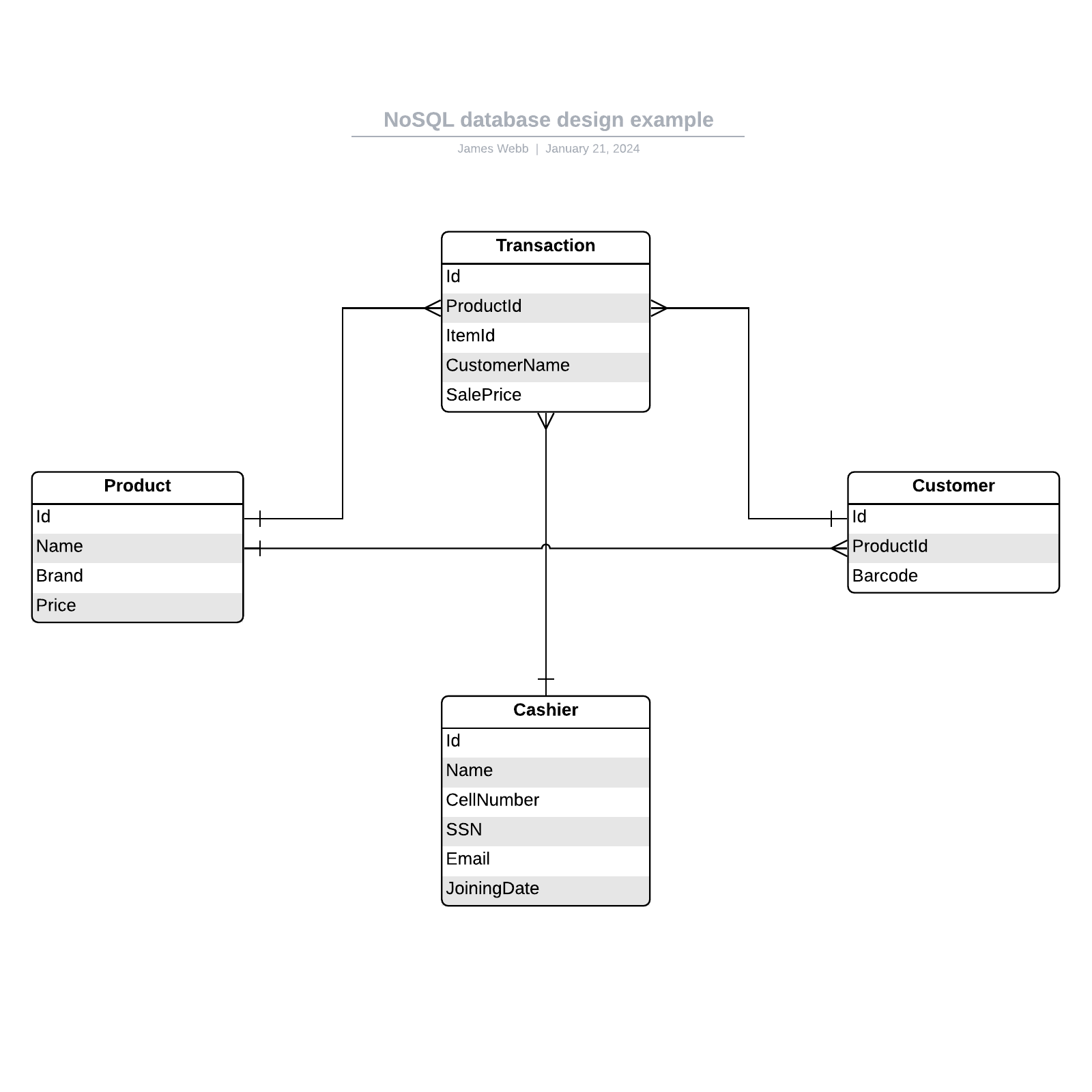
Relationales Modell
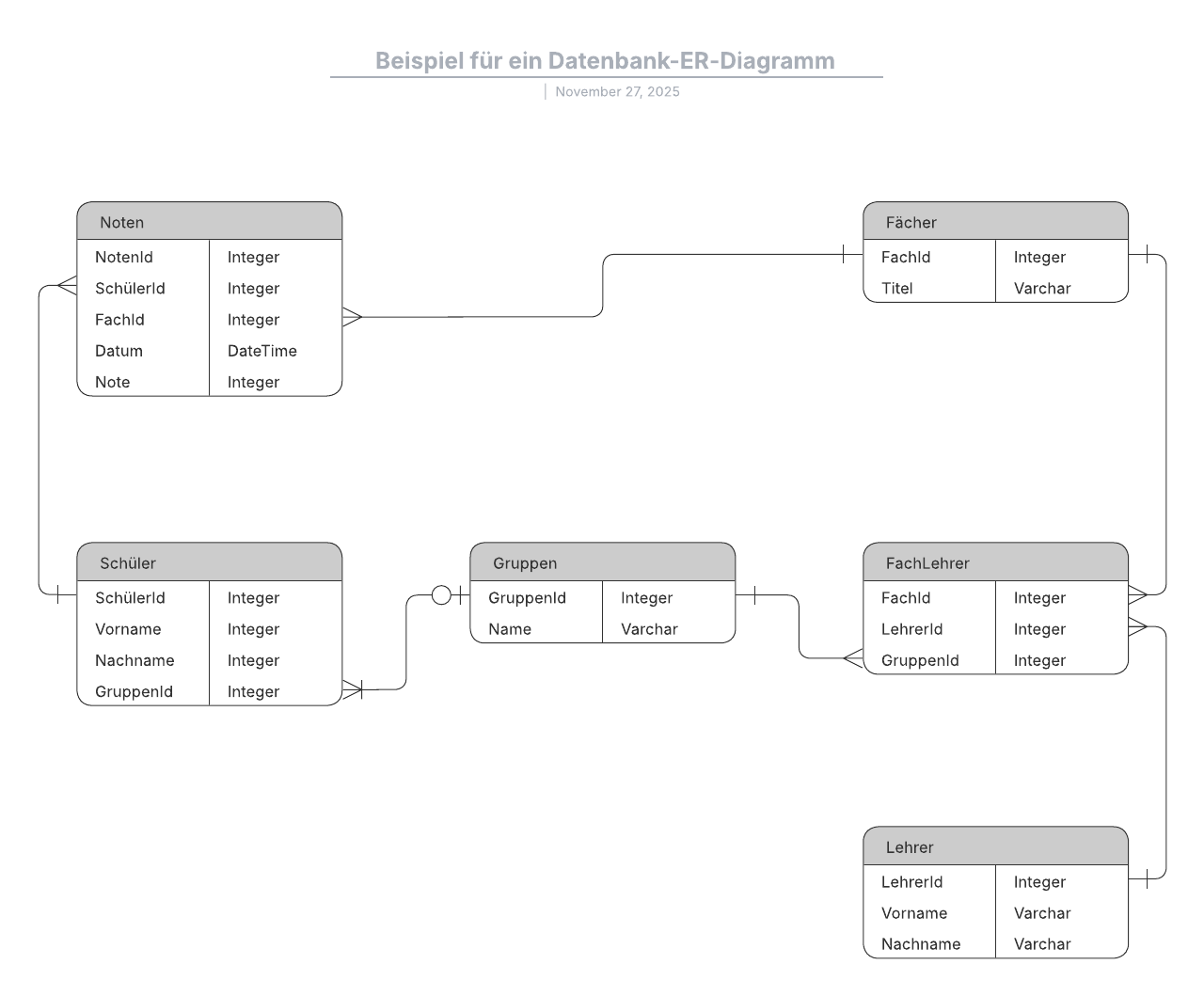
Das am häufigsten verwendete Modell ist das relationale. Dabei werden Daten in Tabellen, auch Relationen genannt, sortiert; jede besteht aus Spalten und Zeilen. In jeder Spalte ist das Attribut der jeweiligen Entität aufgeführt, zum Beispiel Preis, Postleitzahl oder Geburtsdatum. Zusammen werden die Attribute in einer Relation als Domäne bezeichnet. Ein bestimmtes Attribut oder eine Kombination von Attributen wird als Primärschlüssel ausgewählt, auf den in anderen Tabellen verwiesen werden kann (in diesem Fall ist es ein Fremdschlüssel).
Jede Zeile, die auch als Tupel bezeichnet wird, enthält Daten über eine bestimmte Instanz der jeweiligen Entität, zum Beispiel einen speziellen Mitarbeiter.
Das Modell erfasst außerdem die Arten der Beziehungen zwischen diesen Tabellen, darunter 1:1-, 1:m-, und n:m-Beziehungen. Hier ist ein Beispiel:

Innerhalb der Datenbank können Tabellen normalisiert oder zur Erfüllung von Normalisierungsregeln gebracht werden, durch welche die Datenbank flexibel, anpassungsfähig und skalierbar wird. Nach der Normalisierung ist jedes Datenstück atomar, d. h. auf die kleinste nützliche Einheit reduziert.
Relationale Datenbanken werden üblicherweise in SQL (Structured Query Language) geschrieben. Das Modell wurde 1970 von E. F. Codd vorgestellt.
Hierarchisches Modell
Das hierarchische Modell organisiert Daten in einer baumähnlichen Struktur, in der jeder Eintrag eine einzige übergeordnete Einheit oder einen Stamm hat. Geschwistereinträge werden in einer bestimmten Reihenfolge sortiert, welche als physische Reihenfolge zum Speichern der Datenbank dient. Dieses Modell eignet sich gut zur Beschreibung vieler Beziehungen aus der Praxis.

Das Modell wurde hauptsächlich in den 60er und 70er Jahren von den Informationsmanagement-Systemen von IBM verwendet, kommt aber heute aufgrund von operativen Ineffizienzen nur noch selten zum Einsatz.
Netzwerkmodell
Das Netzwerkmodell baut auf das hierarchische Modell auf und ermöglicht Viele-zu-viele-Beziehungen zwischen verknüpften Einträgen, was mehrere übergeordnete Einträge impliziert. Anhand der mathematischen Mengentheorie wird das Modell mit Mengen verwandter Einträge konstruiert. Jede Menge besteht aus einem Eigentümer oder übergeordneten Eintrag und einem oder mehreren Mitgliedern oder untergeordneten Einträgen. Ein Eintrag kann Mitglied mehrerer Mengen bzw. mehreren Mengen untergeordnet sein, sodass mit diesem Modell auch komplexe Beziehungen dargestellt werden können.
Es war in den 70er Jahren sehr beliebt, nachdem es von der CODASYL (Conference on Data Systems Languages; deutsch Konferenz zu Datensystemsprachen) definiert wurde.

Objektorientiertes Datenbankmodell
Dieses Modell definiert eine Datenbank als Ansammlung von Objekten oder wiederverwendbaren Software-Elementen mit assoziierten Funktionen und Methoden. Es gibt mehrere Arten von objektorientierten Datenbanken:
Eine Multimedia-Datenbank enthält Medien wie zum Beispiel Bilder, die nicht in einer relationalen Datenbank gespeichert werden könnten.
Eine Hypertext-Datenbank ermöglicht das Verweisen von Objekten auf andere Objekte. Sie eignet sich zum Organisieren vieler isolierter Daten, ist aber nicht gerade ideal für die numerische Analyse.
Das objektorientierte Datenbankmodell ist das bekannteste post-relationale Datenbankmodell, da es Tabellen einschließt, aber nicht darauf beschränkt ist. Diese Modelle werden auch als hybride Datenbankmodelle bezeichnet.

Objektrelationales Modell
Dieses hybride Datenbankmodell kombiniert die Einfachheit des relationalen Modells mit einigen erweiterten Funktionen des objektorientierten Datenbankmodells. Es erlaubt Designern im Prinzip, Objekte in die vertraute Tabellenstruktur einzubinden.
Die unterstützten Sprachen und Aufrufschnittstellen umfassen SQL3, herstellerspezifische Sprachen, ODBC, JDBC und patentierte Aufrufschnittstellen als Erweiterungen der Sprachen und Schnittstellen, die im relationalen Modell verwendet werden.
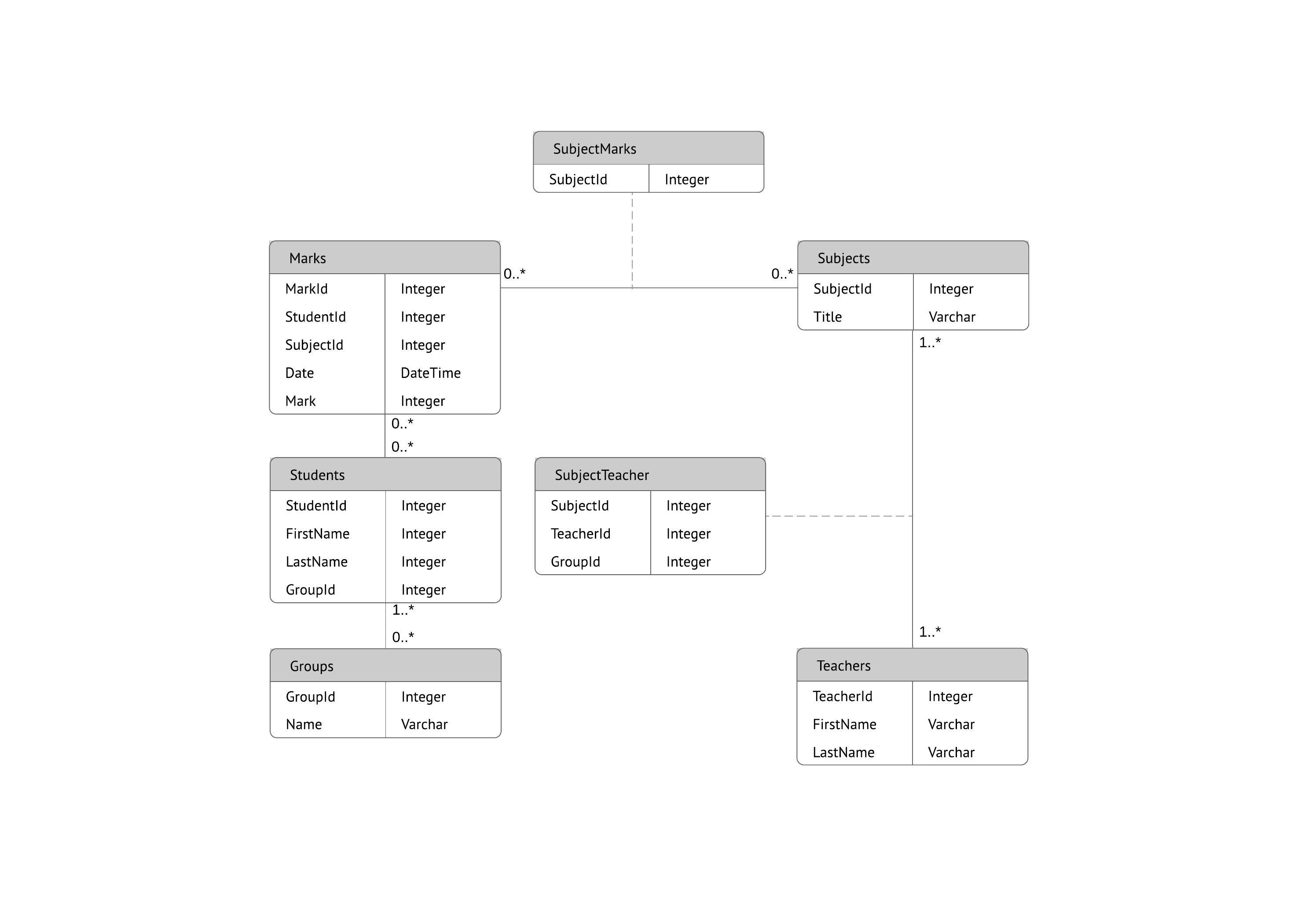
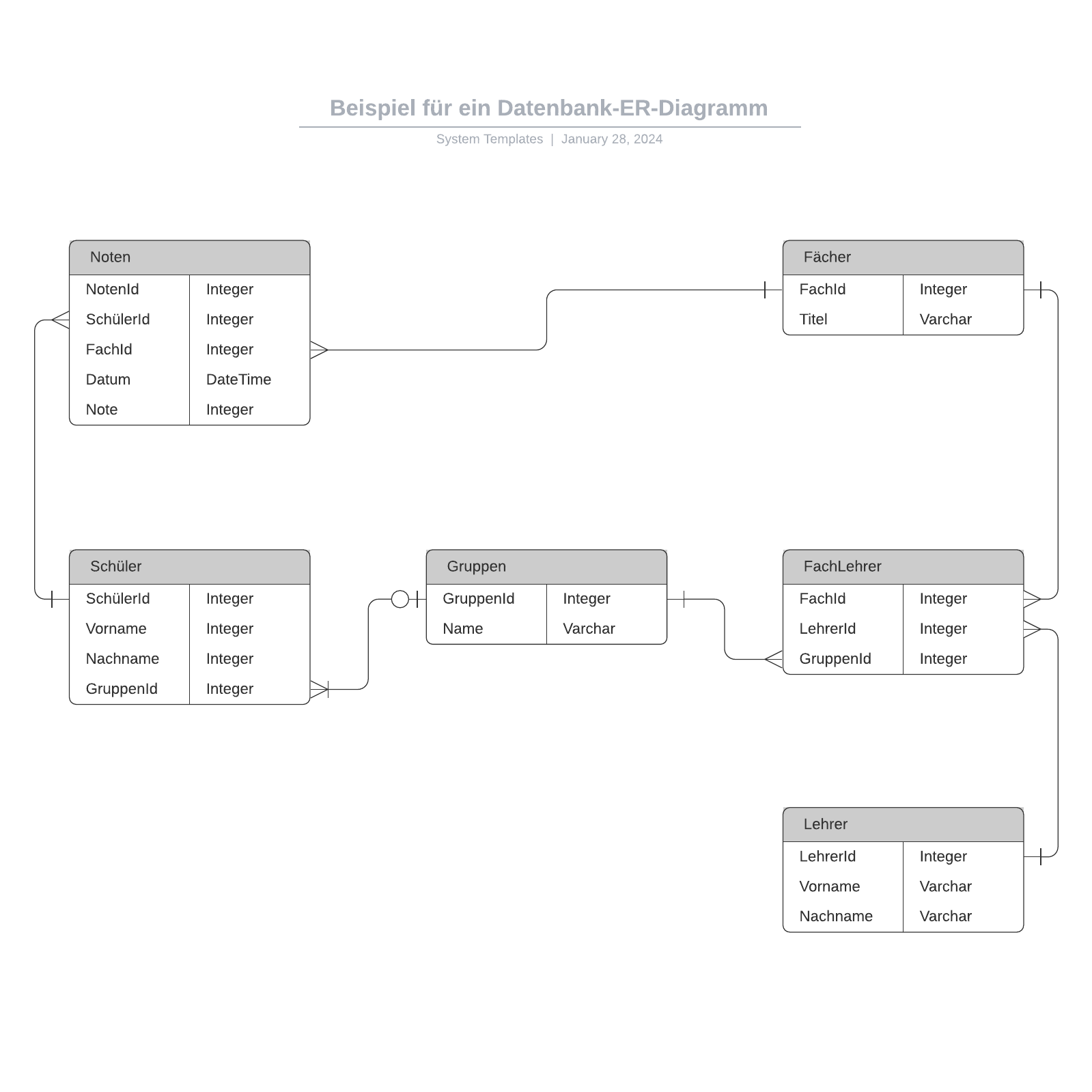
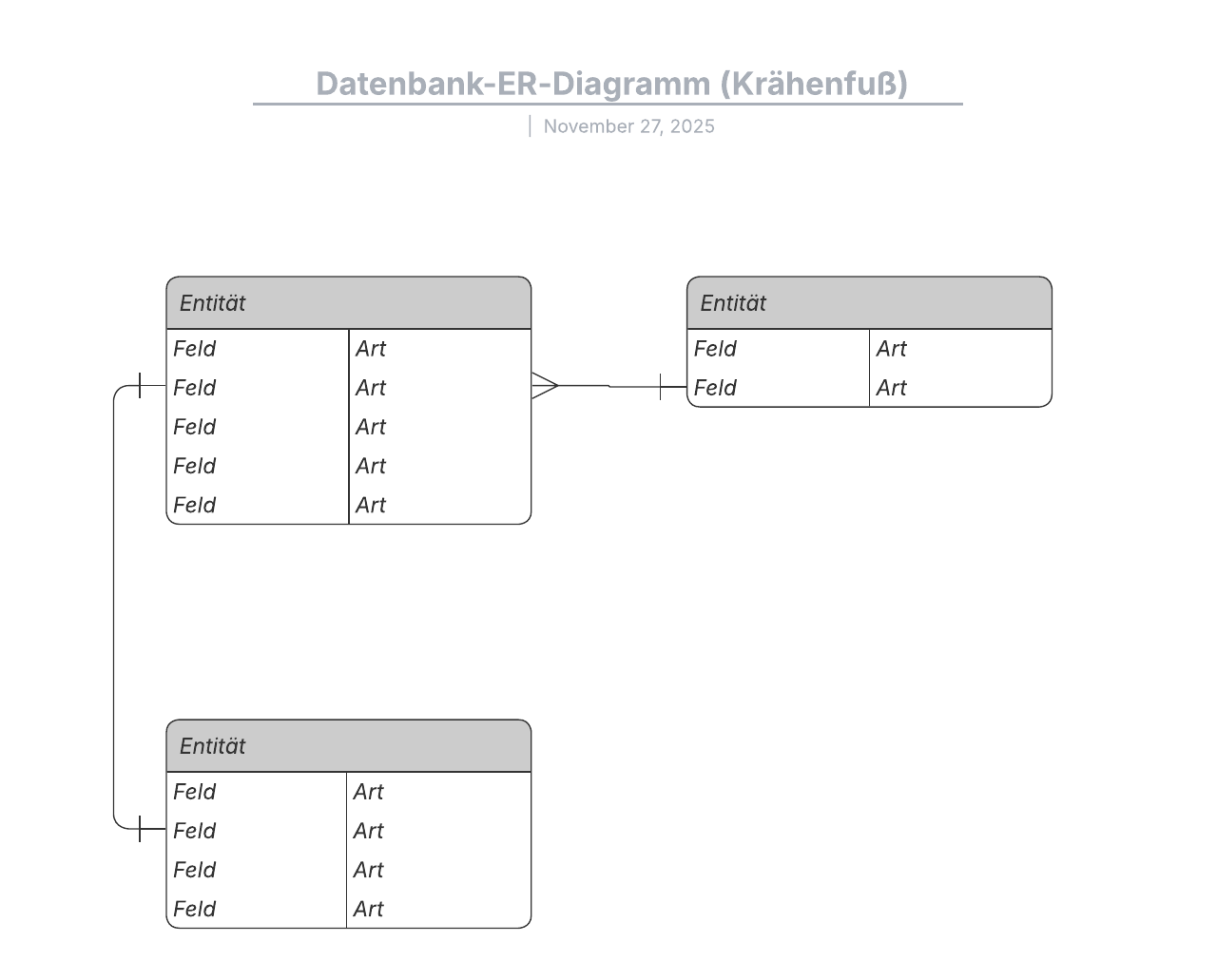
Entity-Relationship-Modell
Dieses Modell erfasst die Beziehungen zwischen realen Entitäten auf ähnliche Weise wie ein Netzwerkmodell, ist aber nicht so direkt an die physische Datenbankstruktur gebunden. Stattdessen wird es oft für das konzeptionelle Datenbankdesign verwendet.
Hier werden die Personen, Orte und Dinge, zu denen Datenpunkte gespeichert werden, als Entitäten bezeichnet. Jede davon hat bestimmte Attribute, die zusammen ihre Domäne bilden. Die Kardinalität bzw. die Beziehungen zwischen den Entitäten wird/werden ebenfalls dargestellt.

Ein häufig verwendete Form des ER-Diagramms ist das Sternschema, in dem eine zentrale Faktentabelle mit mehreren Dimensionstabellen verbunden ist.
Andere Datenbankmodelle
Heute werden immer noch zahlreiche andere Datenbankmodelle verwendet.
Invertiertes Dateimodell
Eine Datenbank auf Grundlage der invertierten Dateistruktur soll Volltextsuchen beschleunigen. In diesem Modell werden die Dateninhalte als eine Reihe von Schlüsseln in einer Nachschlagetabelle indexiert, sodass die Werte auf den Speicherort der verknüpften Dateien verweisen. Diese Struktur bietet bei Big Data und Analysen zum Beispiel nahezu unmittelbare Berichtsmöglichkeiten.
Dieses Modell wird vom Datenbank-Managementsystem ADABAS der Software AG seit 1970 verwendet und immer noch unterstützt.
Flaches Modell
Das flache Modell ist das früheste und einfachste Datenmodell. Es führt schlicht alle Daten in einer einzigen Tabelle aus Spalten und Zeilen auf. Um auf die Daten zuzugreifen oder diese zu bearbeiten, muss der Computer die gesamte flache Datei in den Speicher einlesen, sodass dieses Modell außer für kleinste Datenmengen unbrauchbar ist.
Multidimensionales Modell
Dies ist eine Variante des relationalen Modells, dass die analytische Verarbeitung erleichtern und verbessern soll. Das relationale Modell ist für OLTP (Online-Transaktionsverarbeitung) optimiert, dieses Modell jedoch ist auf OLAP (Online-Analyseverarbeitung) ausgelegt.
Jede Zelle in einer mehrdimensionalen Datenbank enthält Daten zu den von der Datenbank verfolgten Dimensionen. Visuell können Sie sich als Ansammlung von Würfeln im Gegensatz zu zweidimensionalen Tabellen vorstellen.
Semistrukturiertes Modell
In diesem Modell werden die Strukturdaten, die üblicherweise im Datenbankschema enthalten sind, in die Daten selbst integriert. Hier ist die Unterscheidung zwischen Daten und Schema bestenfalls undeutlich. Dieses Modell wird zur Beschreibung von Systemen (wie z. B. webbasierten Datenquellen) verwendet, die wir als Datenbanken behandeln, aber nicht in ein Schema zwingen können. Außerdem ist es nützlich zur Beschreibung von Interaktionen zwischen Datenbanken, die nicht auf demselben Schema basieren.
Kontextmodell
Dieses Modell kann Elemente aus anderen Datenbankmodellen nach Bedarf einbinden. Es kombiniert Elemente als objektorientierten, semistrukturierten und Netzwerkmodellen.
Assoziatives Modell
Dieses Modell teilt alle Datenpunkte auf Grundlage dessen ein, ob sie eine Entität oder eine Assoziation beschreiben. In diesem Modell ist eine Entität alles, was unabhängig existiert. Eine Assoziation ist dagegen etwas, was nur in Beziehung zu etwas anderem existiert.
Das assoziative Modell strukturiert die Daten in zwei Mengen:
- Eine Menge mit Elementen, die jeweils eine eindeutige Kennung, einen Namen und einen Typ haben
- Eine Menge von Verknüpfungen, die jeweils eine eindeutige Kennung und eindeutige Kennungen von Quelle, Verb und Ziel haben. Der gespeicherte Fakt steht mit der Quelle in Verbindung und jede der drei Kennungen kann entweder auf eine Verknüpfung oder ein Element verweisen.
Zu sonstigen, weniger üblichen Datenbankmodellen gehören:
- Das semantische Modell, das Informationen zu Bezügen der gespeicherten Daten zur Realität enthält
- Die XML-Datenbank, in der Daten im XML-Format angegeben und sogar gespeichert werden können
- Named Graph
- Triplestore
NoSQL-Datenbankmodelle
Zusätzlich zum objektbasierten Datenbankmodell haben sich andere Datenbankmodelle ohne SQL gegenüber dem relationalen Modell durchgesetzt:
Das Graphdatenbankmodell, das noch flexibler als ein Netzwerkmodell ist, ermöglicht jedem Knoten die Verbindung mit anderen Knoten.
Das Mehrwertmodell, das sich vom relationalen Modell dadurch unterscheidet, ermöglicht Attributen das Enthalten einer Datenliste anstelle eines einzelnen Datenpunkts.
Das dokumentenorientierte Modell, das auf das Speichern und Verwalten von Dokumenten oder halbstrukturierten Daten anstelle von atomaren Daten ausgelegt ist.
Datenbanken im Netz
Die meisten Websites nutzen eine Datenbank, um Daten zu organisieren und den Benutzern zu präsentieren. Immer, wenn jemand die Suchfunktion auf einer Website benutzt, wird sein Suchbegriff in eine Abfrage umgewandelt, die der Datenbankserver verarbeiten muss. Üblicherweise wird der Webserver über Middleware mit der Datenbank verbunden.
Die starke Präsenz von Datenbanken ermöglicht deren Nutzung in fast jedem Bereich, vom Online-Shopping über das Micro-Targeting von Wählern bei einer Wahlkampagne. Viele Branchen von der Luftfahrt bis zur Fahrzeugfertigung haben ihre eigenen Normen für das Datenbankdesign entwickelt.