Wat zijn databases
Een database is een gestructureerde verzameling informatie die wordt gebruikt om gegevens systematisch te organiseren en op te slaan, en om deze efficiëntte beheren. Een database fungeert als basis voor het centraal beheren van verschillende gegevens en het snel en accuraat ophalen van informatie als dat nodig is.
De databank heeft de volgende kenmerken:
- Gegevens ordenen en structureren: Gegevens zijn georganiseerd in structuren zoals tabellen en velden. Hierdoor kun je gerelateerde gegevens efficiënt opslaan en ophalen.
- Gegevensconsistentie en -integriteit: Databasesystemen kunnen regels en beperkingen instellen om de gegevensconsistentie te behouden. Dit verbetert de nauwkeurigheid en betrouwbaarheid van de gegevens.
- Efficiënte toegang: Databases bieden zoek- en filtermogelijkheden om snel de gegevens te vinden die je nodig heeft.
- Gelijktijdige toegang en delen: Meerdere gebruikers hebben tegelijkertijd toegang tot de database en kunnen gegevens delen. Dit maakt het gemakkelijker om informatie te delen binnen je team of organisatie.
- Beveiliging en back-up: Databases bieden functies voor toegangsrechten beheer en gegevensback-up om de veiligheid van gegevens te garanderen.
Databases zijn belangrijke hulpmiddelen die de organisatie, het beheer en het gebruik van informatie in uiteenlopende situaties ondersteunen, van het dagelijks leven tot het bedrijfsleven. Het wordt bijvoorbeeld op een groot aantal verschillende gebieden gebruikt, waaronder productcatalogi voor online winkelsites, patiëntendossiers voor ziekenhuizen, financiële gegevens voor bedrijven en prestatiebeheersystemen voor scholen.
Een databasebeheersysteem (DBMS) is software voor het maken, beheren en manipuleren van databases en helpt deze efficiënt te werken. Er zijn verschillende soorten DBMS, zoals Oracle, MySQL, PostgreSQL en Microsoft SQL Server. Elk DBMS heeft verschillende functies en kenmerken en wordt geselecteerd afhankelijk van het doel en de behoeften.
Lees onder het filmpje meer over de verschillende datamodellen en structuren en over best practices voor het ontwerpen van databases.
In minder dan 5 minuten aan de slag met Lucidchart
- Gebruik onze online tool om je eerste online diagram te maken op basis van een sjabloon of leeg canvas of importeer een document.
- Voeg tekst, vormen en lijnen toe om je stroomdiagram aan te passen.
- Meer informatie over het aanpassen van de stijl en opmaak in je stroomdiagram.
- Vind wat je nodig hebt met 'Functie zoeken'.
- Deel je stroomdiagram met je team om samen te werken.
Ontwerpproces van de database
Een goed gestructureerde database:
- Bespaart schijfruimte door overbodige gegevens te elimineren.
- Behoudt de nauwkeurigheid en integriteit van gegevens.
- Biedt op een nuttige manier toegang tot de gegevens.
Een efficiënte, nuttige database ontwerpen is een kwestie van het volgen van het juiste proces, inclusief deze fases:
- Behoefteanalyse of het doel van uw database bepalen
- Gegevens ordenen in tabellen
- Primaire sleutels specificeren en relaties analyseren
- Normalisatie om de tabellen te standaardiseren
Laten we elke stap eens nader bekijken. Bedenk dat deze leidraad het in SQL geschreven relationele-databasemodel van Edgar Codd behandelt (in plaats van het hiërarchische, netwerk- of objectgeöriënteerde datamodel). Wilt u meer weten over databasemodellen? Lees dan hier onze gids.
Behoefteanalyse: het doel van de database bepalen
Met inzicht in het doel van uw database maakt u tijdens het ontwerpproces doordachte keuzes. Zorg ervoor dat u de database vanuit elke invalshoek bekijkt. Stel, u maakt een database voor een openbare bibliotheek. U moet dan rekening houden met de manieren waarop zowel leners als bibliotheekmedewerkers toegang tot de gegevens kunnen krijgen.
Hier zijn een aantal manieren om informatie te verzamelen, voordat er een database wordt gemaakt:
- Overleg met de mensen die hem gaan gebruiken
- Analyseer bedrijfsformulieren, zoals facturen, urenstaten en enquêtes
- Pluis alle bestaande datasystemen (inclusief fysieke en digitale bestanden) uit
Begin met het verzamelen van bestaande gegevens die in de database zullen worden opgenomen. Maak daarna een lijst van de soorten gegevens die u wilt opslaan en van de entiteiten of mensen, voorwerpen, locaties en gebeurtenissen die door die gegevens worden beschreven, zoals:
Klanten
- Naam
- Adres
- Woonplaats, provincie, postcode
- E-mailadres
Producten
- Naam
- Prijs
- Aantal op voorraad
- Aantal op bestelling
Bestellingen
- Bestellings-ID
- Vertegenwoordiger
- Datum
- Product(en)
- AANTAL
- Prijs
- Totaal
Deze informatie zal later deel uitmaken van het gegevenswoordenboek, een samenvatting van de tabellen en velden in de database. Splits de informatie uit in de kleinste, bruikbare stukjes. Overweeg bijvoorbeeld om de straatnaam van het land te scheiden, zodat u personen later kunt filteren op hun thuisland. Voorkom ook dat hetzelfde gegevenspunt in meer dan een tabel wordt gezet, want dit zorgt ervoor dat het onnodig ingewikkeld wordt.
Zodra u weet wat voor soort gegevens de database zal bevatten, waar die gegevens vandaan komen en hoe ze zullen worden gebruikt, kunt u beginnen met het samenstellen van de eigenlijke database.
Databasestructuur: de bouwstenen van een database
De volgende stap is het ontwerpen van een visuele weergave van uw database. Daarvoor moet u precies weten hoe relationele databases zijn opgebouwd.
In een database zijn verwante gegevens samengevoegd in tabellen, die elk uit rijen (ook wel tupels genoemd) en kolommen bestaan, net zoals een spreadsheet.
Als u uw lijsten met gegevens naar tabellen wilt omzetten, maakt u eerst een tabel voor elke soort entiteit, zoals producten, verkoop, klanten en bestellingen. Een voorbeeld:
Elke rij van een tabel wordt een record genoemd. Records bevatten gegevens over iets of iemand, zoals over een bepaalde klant. Kolommen (ook wel velden of attributen genoemd), daarentegen, bevatten één soort informatie die in elk record voorkomt, zoals de adressen van alle klanten die in de tabel staan vermeld.
| Voornaam | Achternaam | Leeftijd | Postcode |
|---|---|---|---|
| Roger | Williams | 43 | 34760 |
| Jerrica | Jorgensen | 32 | 97453 |
| Samantha | Hopkins | 56 | 64829 |
Als u de gegevens van het ene naar het andere record consistent wilt houden, wijst u aan elke kolom het juiste gegevenstype toe. Enkele gangbare gegevenstypes:
- CHAR - tekst van specifieke lengte
- VARCHAR - tekst van variabele lengte
- TEXT - grote hoeveelheden tekst
- INT - positief of negatief heel getal
- FLOAT, DOUBLE - kan ook zwevendekommagetallen opslaan
- BLOB - binaire gegevens
Sommige databasemanagementsystemen bieden ook het gegevenstype Autonumber dat in elke rij automatisch een uniek getal genereert.
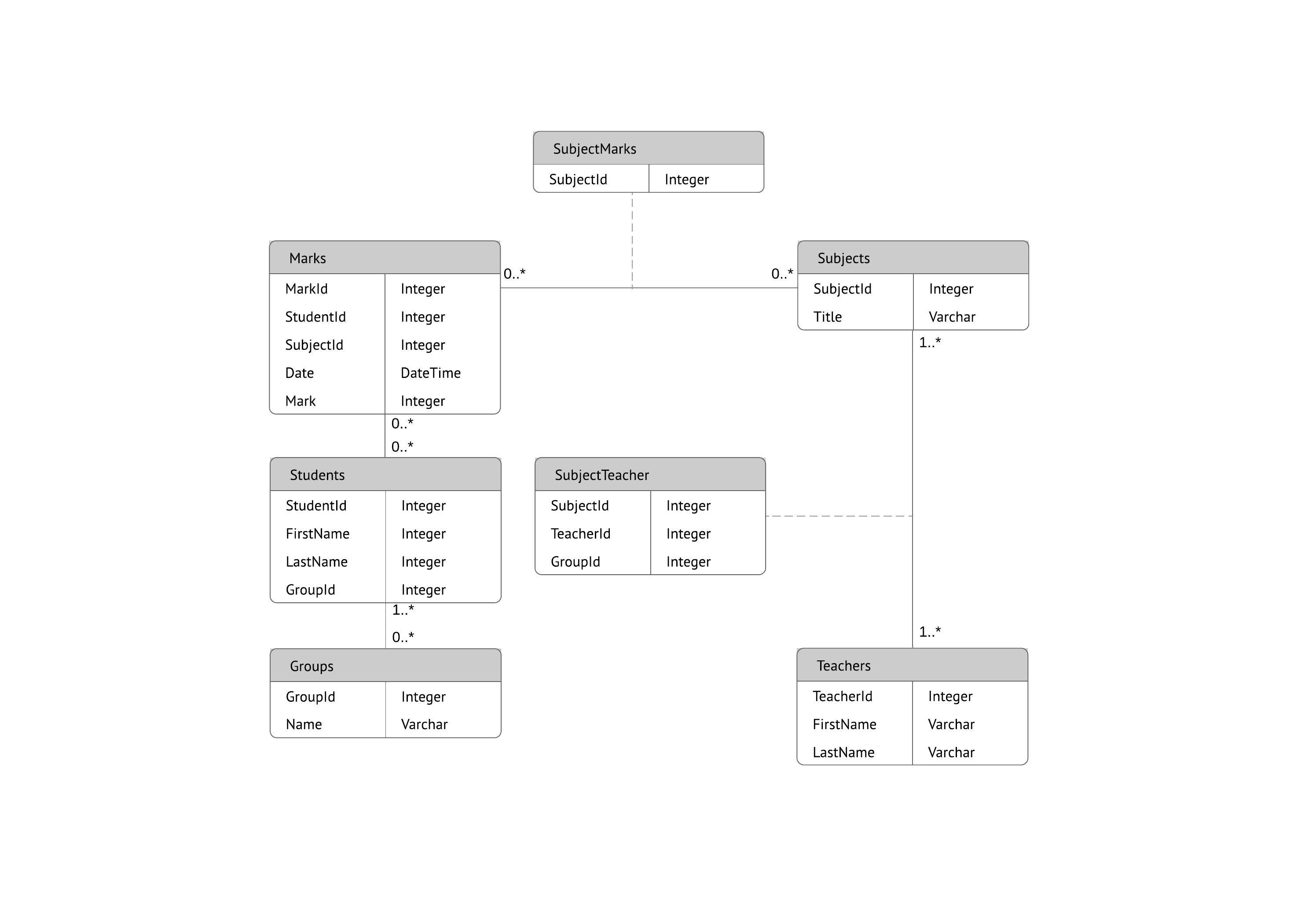
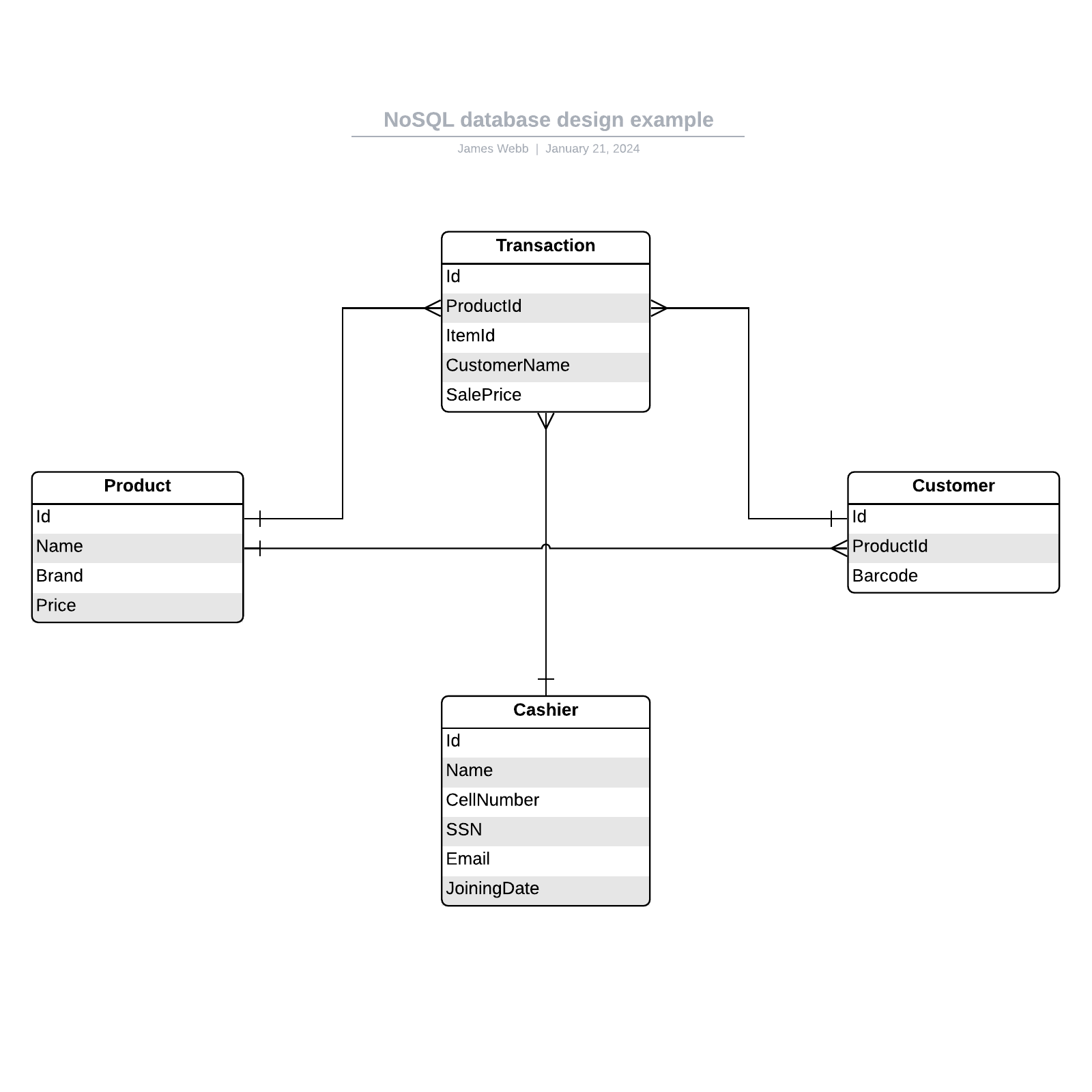
Voor het creëren van een visueel overzicht van de database, een zogeheten entity-relationship diagram, gebruikt u niet de eigenlijke tabellen. In plaats daarvan wordt elke tabel een vak in het diagram. De naam van elk vak moet aangeven wat de gegevens in die tabel beschrijven, terwijl de attributen daaronder worden vermeld, als volgt:

Tot slot moet u bepalen welk attribuut of welke attributen als de primaire sleutel voor elke tabel zal/zullen fungeren, indien van toepassing. Een primaire sleutel (PK) is een unieke identificatiecode voor een bepaalde entiteit. Dit betekent dat u de juiste klant kunt selecteren, zelfs als u alleen die waarde kent.
Attributen die als primaire sleutels zijn gekozen, moeten uniek, onveranderlijk en altijd aanwezig (nooit NULL of leeg) zijn. Daarom zijn bestelnummers en gebruikersnamen goede primaire sleutels, maar telefoonnummers of straatnamen niet. U kunt ook meerdere gecombineerde velden als primaire sleutel (een zogeheten samengestelde sleutel) gebruiken.
Als het tijd is om de eigenlijke database te maken, zet u de logische gegevensstructuur en de fysieke gegevensstructuur in de door uw databasemanagementsysteem ondersteunde data definition language. Op dat moment moet u ook een inschatting maken van de omvang van de database, om er zeker van te zijn dat u het vereiste prestatieniveau en de vereiste opslagruimte kunt krijgen.
Entiteitsrelaties maken
Nu uw gegevens naar tabellen zijn omgezet, kunt u de relaties tussen die tabellen analyseren. Kardinaliteit verwijst naar de hoeveelheid elementen die een wisselwerking hebben tussen twee verwante tabellen. Door de kardinaliteit te bepalen, weet u zeker dat u de gegevens het efficiëntst in tabellen hebt verdeeld.
Elke entiteit kan een relatie met iedere andere hebben, maar die relaties zijn gewoonlijk een van drie types:
Een-op-een-relaties
Als er maar een entiteit A is voor iedere entiteit B is er sprake van een een-op-een-relatie (vaak geschreven als 1:1). U kunt dit type relatie in een ER-diagram aangeven door middel van een lijn met een streepje aan beide kanten:

Tenzij u een goede reden hebt om dit niet te doen, is een 1:1-relatie meestal een indicatie dat u de gegevens uit de twee tabellen beter kunt combineren in één tabel.
Het kan echter zo zijn dat u, onder bepaalde omstandigheden, tabellen wilt maken met een 1:1-relatie. Als u een veld met optionele gegevens hebt, zoals “beschrijving,” dat bij veel van de records blanco is, dan kunt u alle beschrijvingen naar hun eigen tabel verplaatsen. Hiermee verwijdert u de lege ruimte en verbetert u de prestaties van de database.
Om te garanderen dat de gegevens goed overeenkomen, moet u minstens een identieke kolom in elke tabel opnemen. Dat is dan hoogstwaarschijnlijk de primaire sleutel.
Een-op-veel-relaties
Deze relaties ontstaan als een record in een tabel gerelateerd is aan meerdere gegevens in een andere tabel. Bijvoorbeeld: een klant heeft veel bestellingen geplaatst, of een lener heeft veel boeken in een keer geleend bij de bibliotheek. Een-op-veel-relaties (1:M-relaties) worden weergegeven met de zogeheten “kraaienpootnotatie,” zoals in dit voorbeeld:

Als u bij het opzetten van een database een 1:M-relatie wilt implementeren, voegt u gewoon de primaire sleutel van de “ene” kant van de relatie als attribuut toe in de andere tabel. Als een primaire sleutel op deze manier in een andere tabel staat, wordt deze een refererende sleutel genoemd. De tabel aan de “1”-kant van de relatie wordt beschouwd als een oudertabel ten opzichte van de kindtabel aan de andere kant.
Veel-op-veel-relaties
Als meerdere entiteiten uit een tabel kunnen worden gerelateerd aan meerdere entiteiten in een andere tabel, is er sprake van een veel-op-veel-relatie (M:N-relatie). Dit gebeurt bijvoorbeeld bij studenten en colleges, want een student kan veel colleges volgen en een college kan door veel studenten worden gevolgd.
In een ER-diagram worden deze relaties weergegeven met deze lijnen:

Helaas kan een relatie van dit type niet rechtstreeks in de database worden geïmplementeerd. U moet het opsplitsen in twee een-op-veel-relaties.
Hiervoor maakt u een nieuwe entiteit aan tussen die twee tabellen. Bestaat de M:N-relatie tussen verkoop en producten, dan kunt u die nieuwe entiteit “verkochte_producten” noemen, omdat hij de inhoud van elke verkoop laat zien. De tabellen verkoop en producten hebben dan een 1:M-relatie met verkochte_producten. Dit type tussenentiteit wordt in diverse modellen een koppeltabel, associatieve entiteit of verbindingstabel genoemd.
Elk record in de koppeltabel zou twee van de entiteiten in de aangrenzende tabellen koppelen (en kan zelfs aanvullende informatie bevatten). Een koppeltabel tussen studenten en colleges, bijvoorbeeld, zou er als volgt uit kunnen zien:

Wel of niet verplicht?
Een andere manier om relaties te analyseren is te bekijken welke kant van de relatie moet bestaan, opdat de andere ook bestaat. De niet-verplichte kant kan met een cirkel worden gemarkeerd op de lijn waar anders een streepje zou staan. Bijvoorbeeld: Een land moet bestaan om een vertegenwoordiger in de Verenigde Naties te hebben, maar het omgekeerde is niet waar:

Twee entiteiten kunnen onderling afhankelijk zijn (de ene zou niet kunnen bestaan zonder de andere).
Recursieve relaties
Soms verwijst een tabel naar zichzelf. Een tabel van medewerkers, bijvoorbeeld, kan een attribuut “manager” hebben dat naar een andere persoon in diezelfde tabel verwijst. Dit wordt een recursieve relatie genoemd.
Redundante relaties
Een redundante relatie is een relatie die meer dan eens wordt uitgedrukt. U kunt doorgaans een van de relaties verwijderen zonder dat er belangrijke informatie verloren gaat. Als, bijvoorbeeld, een entiteit “studenten” een directe relatie heeft met een andere entiteit genaamd “docenten”, maar door “colleges” ook indirect een relatie heeft met docenten, wilt u de relatie tussen “studenten” en “docenten” verwijderen. Het is beter die relatie te verwijderen, want de enige manier waarop studenten worden toegewezen aan docenten is door colleges.
Databasenormalisatie
Zodra u een voorlopig ontwerp voor uw database hebt, kunt u normalisatieregels toepassen om ervoor te zorgen dat de tabellen goed gestructureerd zijn. U kunt deze regels als de industrienorm beschouwen.
Echter, niet alle databases komen voor normalisatie in aanmerking. In het algemeen moeten databases voor online transaction processing (OLTP), waarin gebruikers te maken hebben met het aanmaken, lezen, updaten en verwijderen van records, worden genormaliseerd.
Databases voor online analytical processing (OLAP), die het analyseren en rapporteren bevorderen, doen het waarschijnlijk beter met een zekere mate van denormalisatie, want daarbij ligt de nadruk op rekensnelheid. Deze bevatten toepassingen voor beslissingsondersteuning waarin gegevens snel moeten worden geanalyseerd maar niet gewijzigd.
Iedere vorm van normalisatie of ieder normalisatieniveau omvat regels die met de lagere vormen zijn verbonden.
Eerste normaalvorm
De eerste normaalvorm (afgekort: 1NF) geeft aan dat elke cel in de tabel maar één waarde kan hebben, nooit een lijst van waardes. Een tabel zoals deze voldoet dus niet:
| Product-ID | Kleur | Prijs |
|---|---|---|
| 1 | bruin, geel | $15 |
| 2 | rood, groen | $13 |
| 3 | blauw, oranje | $11 |
U komt misschien in de verleiding om dit te omzeilen door die gegevens in extra kolommen op te splitsen, maar ook dat is tegen de regels: een tabel met groepen herhaalde of nauw verwante attributen voldoet niet aan de eerste normaalvorm. De tabel hieronder, bijvoorbeeld, voldoet niet:

Splits, in plaats daarvan, de gegevens op in meerdere tabellen of records, totdat elke cel nog maar één waarde bevat en er geen extra kolommen zijn. Dan zijn de gegevens atomair of uitgesplitst naar de kleinst bruikbare grootte. Voor bovenstaande tabel zou u een extra tabel “Verkoopgegevens” kunnen aanmaken die specifieke producten aan verkoop koppelt. “Verkoop” zou dan een 1:M-relatie hebben met “Verkoopgegevens”.
Tweede normaalvorm
De tweede normaalvorm (2NF) bepaalt dat elk van de attributen volledig afhankelijk moet zijn van de gehele primaire sleutel. Dit betekent dat elk attribuut direct van de primaire sleutel afhankelijk moet zijn in plaats van indirect via een ander attribuut.
Een attribuut “leeftijd”, bijvoorbeeld, dat afhankelijk is van “geboortedatum” dat op zijn beurt afhankelijk is van “student-ID”, heeft een partiële functionele afhankelijkheid en een tabel die deze attributen bevat, voldoet niet aan de tweede normaalvorm.
Bovendien is een tabel met een primaire sleutel bestaande uit meerdere velden in strijd met de tweede normaalvorm als een of meer van de andere velden niet afhankelijk zijn van elk deel van de sleutel.
Een tabel met deze velden zou dus niet voldoen aan de tweede normaalvorm omdat het attribuut “productnaam” afhankelijk is van de product ID, maar niet van het bestelnummer:
-
Bestelnummer (primaire sleutel)
-
Product-ID (primaire sleutel)
- Productnaam
Derde normaalvorm
De derde normaalvorm (3NF) voegt aan deze regels de eis toe dat iedere niet-sleutelkolom onafhankelijk moet zijn van iedere andere kolom. Als door wijziging van een waarde in één niet-sleutelkolom een andere waarde verandert, voldoet die tabel niet aan de derde normaalvorm.
Hierdoor slaat u geen afgeleide gegevens in de tabel op, zoals onderstaande “Btw”-kolom, die direct afhankelijk is van de totale prijs van de bestelling:
| Bestelling | Prijs | Btw |
| 14325 | $40.99 | $2.05 |
| 14326 | $13.73 | $.69 |
| 14327 | $24.15 | $1.21 |
Er zijn aanvullende vormen van normalisatie voorgesteld, waaronder de Boyce-Codd-normaalvorm, de vierde tot en met zesde normaalvorm, en de domein/sleutel normaalvorm, maar de eerste drie zijn de meest gangbare.
Hoewel deze vormen de over het algemeen te volgen beste werkwijze uiteenzetten, hangt de mate van normalisatie af van de context van de database.
Multidimensionale gegevens
Sommige gebruikers willen toegang kunnen krijgen tot meerdere dimensies van één soort gegevens, vooral in OLAP-databases. Ze willen bijvoorbeeld weten wat de omzet per klant, land en maand is. In dat geval is het het beste om een centrale feitentabel te maken waar ander klant-, land- en maandtabellen naar kunnen verwijzen, zoals deze:

Regels voor gegevensintegriteit
Ook dient u uw database te configureren om de gegevens volgens de juiste regels te valideren. Veel databasemanagementsystemen, zoals Microsoft Access, dwingen sommige van deze regels automatisch af.
Volgens de entiteit-integriteitsregel kan de primaire sleutel nooit NULL zijn. Als de sleutel uit meerdere kolommen bestaat, kan geen enkele daarvan NULL zijn. Anders zou hij er niet in slagen het record eenduidig te herkennen.
De referentiële-integriteitsregel vereist dat elke refererende sleutel die in één tabel staat, wordt gekoppeld aan één primaire sleutel in de tabel waarnaar hij verwijst. Als de primaire sleutel verandert of is verwijderd, moeten die wijzigingen overal worden toegepast waar er in de database naar die sleutel wordt verwezen.
De integriteitsregels voor bedrijfslogica zorgen ervoor dat de gegevens binnen bepaalde logische parameters passen. Een afspraak, bijvoorbeeld, zou binnen de normale kantooruren moeten vallen.
Indexen en weergaven toevoegen
Een index is in wezen een gesorteerde kopie van een of meer kolommen, met de waardes in oplopende of aflopende volgorde. Een index toevoegen helpt gebruikers om records sneller te vinden. In plaats van voor elke query opnieuw te sorteren, kan het systeem toegang tot records krijgen in de door de index aangegeven volgorde.
Hoewel indexen het ophalen van gegevens versnellen, kunnen ze het opnemen, updaten en verwijderen ervan vertragen. De index moet namelijk iedere keer als een record wordt gewijzigd weer opnieuw worden opgebouwd.
Een view is gewoon een opgeslagen query over de gegevens. Zij kunnen heel handig gegevens uit meerdere tabellen bij elkaar zetten of een deel van een tabel laten zien.
Uitgebreide eigenschappen
Zodra u de basisindeling hebt afgerond, kunt u de database verfijnen met uitgebreide eigenschappen zoals instructietekst, invoermaskers en formatteringsregels die gelden voor een specifiek schema, een specifieke view of kolom. Het voordeel is dat de gegevens consistent worden weergegeven door de diverse programma's die toegang hebben tot de gegevens omdat deze regels in de database zelf zijn opgeslagen.
SQL en UML
Unified Modeling Language (UML) is een andere visuele manier om complexe systemen weer te geven die in een objectgeoriënteerde taal zijn gemaakt. Diverse concepten die in deze gids worden genoemd, staan in UML onder verschillende namen bekend. Een entiteit, bijvoorbeeld, wordt in UML een klasse genoemd.
Tegenwoordig wordt UML niet meer zo vaak gebruikt als vroeger. Nu wordt hij vaak wetenschappelijk en in de communicatie tussen softwareontwikkelaars en hun klanten gebruikt.
Databasemanagementsystemen
Veel van de ontwerpkeuzes die u zult maken, hangen af van het databasemanagementsysteem dat u gebruikt. Enkele van de meest gebruikte zijn:
-
Oracle DB
-
MySQL
-
Microsoft SQL Server
-
PostgreSQL
-
IBM DB2
Als u de keuze hebt, kies dan een geschikt databasemanagementsysteem gebaseerd op kosten, besturingssystemen, specificaties enz.