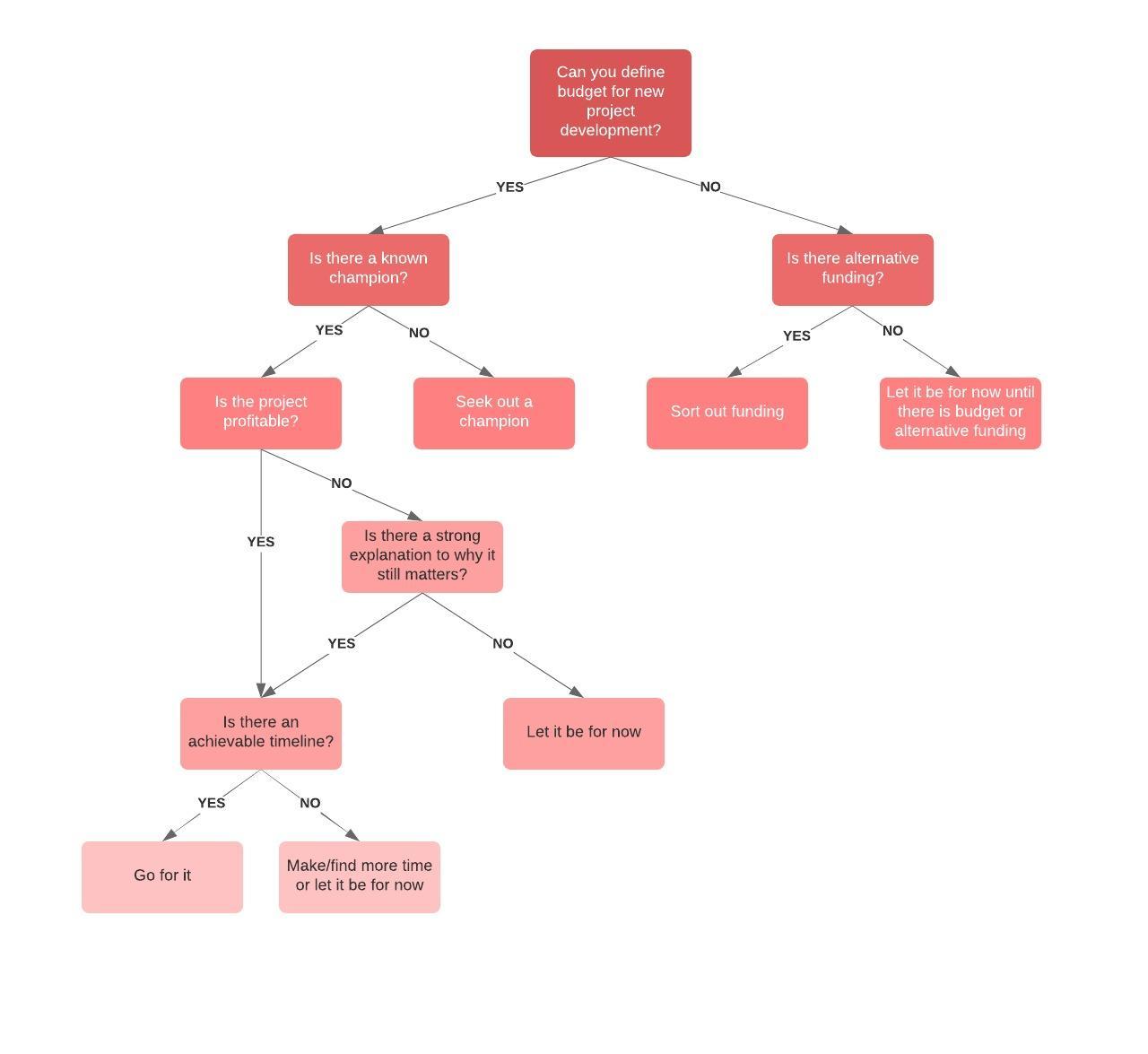
What is a decision tree?
A decision tree is a map of the possible outcomes of a series of related choices. It allows an individual or organization to weigh possible actions against one another based on their costs, probabilities, and benefits. They can can be used either to drive informal discussion or to map out an algorithm that predicts the best choice mathematically.
A decision tree typically starts with a single node, which branches into possible outcomes. Each of those outcomes leads to additional nodes, which branch off into other possibilities. This gives it a treelike shape.
There are three different types of nodes: chance nodes, decision nodes, and end nodes. A chance node, represented by a circle, shows the probabilities of certain results. A decision node, represented by a square, shows a decision to be made, and an end node shows the final outcome of a decision path.

Decision trees can also be drawn with flowchart symbols, which some people find easier to read and understand.
Master the basics of Lucidchart in 3 minutes
- Create your first diagram from a template or blank canvas or import a document.
- Add text, shapes, and lines to customize your diagram.
- Learn how to adjust styling and formatting.
- Locate what you need with Feature Find.
- Share your diagram with your team to start collaborating.
Decision tree symbols
| Shape | Name | Meaning |
|---|---|---|
 | Decision node | Indicates a decision to be made |
 | Chance node | Shows multiple uncertain outcomes |
 | Alternative branches | Each branch indicates a possible outcome or action |
 | Rejected alternative | Shows a choice that was not selected |
 | Endpoint node | Indicates a final outcome |
How to draw a decision tree
To draw a decision tree, first pick a medium. You can draw it by hand on paper or a whiteboard, or you can use special decision tree software. In either case, here are the steps to follow:
1. Start with the main decision. Draw a small box to represent this point, then draw a line from the box to the right for each possible solution or action. Label them accordingly.

2. Add chance and decision nodes to expand the tree as follows:
- If another decision is necessary, draw another box.
- If the outcome is uncertain, draw a circle (circles represent chance nodes).
- If the problem is solved, leave it blank (for now).

From each decision node, draw possible solutions. From each chance node, draw lines representing possible outcomes. If you intend to analyze your options numerically, include the probability of each outcome and the cost of each action.
3. Continue to expand until every line reaches an endpoint, meaning that there are no more choices to be made or chance outcomes to consider. Then, assign a value to each possible outcome. It could be an abstract score or a financial value. Add triangles to signify endpoints.

With a complete decision tree, you’re now ready to begin analyzing the decision you face.
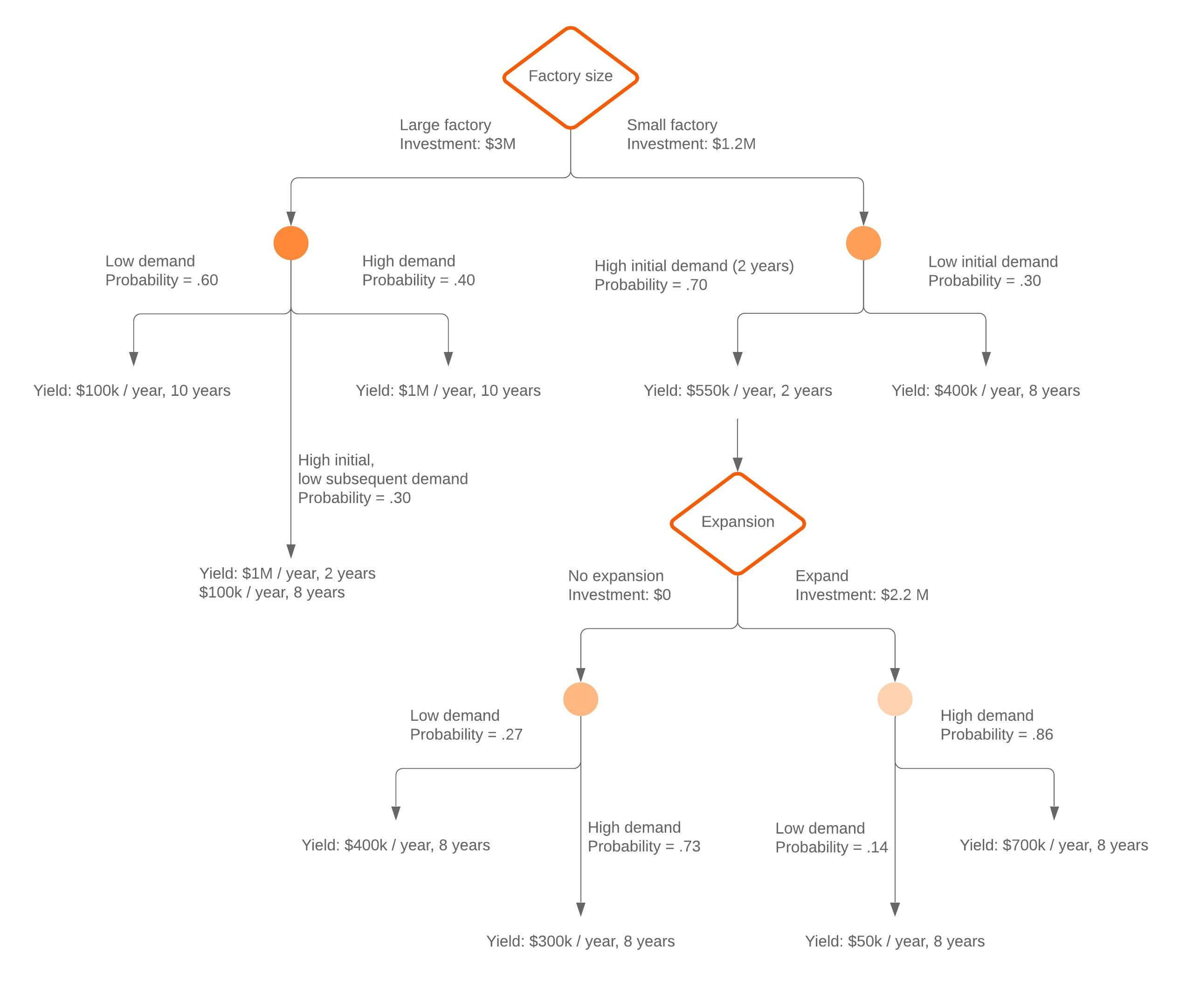
Decision tree analysis example
By calculating the expected utility or value of each choice in the tree, you can minimize risk and maximize the likelihood of reaching a desirable outcome.
To calculate the expected utility of a choice, just subtract the cost of that decision from the expected benefits. The expected benefits are equal to the total value of all the outcomes that could result from that choice, with each value multiplied by the likelihood that it’ll occur. Here’s how we’d calculate these values for the example we made above:

When identifying which outcome is the most desirable, it’s important to take the decision maker’s utility preferences into account. For instance, some may prefer low-risk options while others are willing to take risks for a larger benefit.
When you use your decision tree with an accompanying probability model, you can use it to calculate the conditional probability of an event, or the likelihood that it’ll happen, given that another event happens. To do so, simply start with the initial event, then follow the path from that event to the target event, multiplying the probability of each of those events together.
In this way, a decision tree can be used like a traditional tree diagram, which maps out the probabilities of certain events, such as flipping a coin twice.

Advantages and disadvantages
Decision trees remain popular for reasons like these:
- How easy they are to understand
- They can be useful with or without hard data, and any data requires minimal preparation
- New options can be added to existing trees
- Their value in picking out the best of several options
- How easily they combine with other decision making tools
However, decision trees can become excessively complex. In such cases, a more compact influence diagram can be a good alternative. Influence diagrams narrow the focus to critical decisions, inputs, and objectives.

Decision trees in machine learning and data mining
A decision tree can also be used to help build automated predictive models, which have applications in machine learning, data mining, and statistics. Known as decision tree learning, this method takes into account observations about an item to predict that item’s value.
In these decision trees, nodes represent data rather than decisions. This type of tree is also known as a classification tree. Each branch contains a set of attributes, or classification rules, that are associated with a particular class label, which is found at the end of the branch.
These rules, also known as decision rules, can be expressed in an if-then clause, with each decision or data value forming a clause, such that, for instance, “if conditions 1, 2 and 3 are fulfilled, then outcome x will be the result with y certainty.”
Each additional piece of data helps the model more accurately predict which of a finite set of values the subject in question belongs to. That information can then be used as an input in a larger decision making model.
Sometimes the predicted variable will be a real number, such as a price. Decision trees with continuous, infinite possible outcomes are called regression trees.
For increased accuracy, sometimes multiple trees are used together in ensemble methods:
-
Bagging
creates multiple trees by resampling the source data, then has those trees vote to reach consensus. - A
Random Forest classifier
consists of multiple trees designed to increase the classification rate -
Boosted trees
that can be used for regression and classification trees. - The trees in a
Rotation Forest
are all trained by using PCA (principal component analysis) on a random portion of the data
A decision tree is considered optimal when it represents the most data with the fewest number of levels or questions. Algorithms designed to create optimized decision trees include CART, ASSISTANT, CLS and ID3/4/5. A decision tree can also be created by building association rules, placing the target variable on the right.
Each method has to determine which is the best way to split the data at each level. Common methods for doing so include measuring the Gini impurity, information gain, and variance reduction.
Using decision trees in machine learning has several advantages:
- The cost of using the tree to predict data decreases with each additional data point
- Works for either categorical or numerical data
- Can model problems with multiple outputs
- Uses a white box model (making results easy to explain)
- A tree’s reliability can be tested and quantified
- Tends to be accurate regardless of whether it violates the assumptions of source data
But they also have a few disadvantages:
- When dealing with categorical data with multiple levels, the information gain is biased in favor of the attributes with the most levels.
- Calculations can become complex when dealing with uncertainty and lots of linked outcomes.
- Conjunctions between nodes are limited to AND, whereas decision graphs allow for nodes linked by OR.
Why make a decision tree?
Decisions, decisions—we all have to make them. When a business makes the wrong decision it can be a costly mistake resulting in financial loss, poor use of resources, and negative impact on a company’s image. Thankfully, a decision tree diagram can help. While it’s not a crystal ball, it can provide some valuable insight that can steer you in the right direction. One of the biggest benefits of a decision tree is that it can take emotions out of the equation.
Decision tree diagrams are often used by businesses to plan a strategy, analyze research, and come to conclusions. Lenders and banks use decision trees to calculate the riskiness of loans and investment opportunities. They are also a popular choice for infographics, often appearing in magazines or shared on social media. The point is that decision trees can be used to evaluate just about any question or concern and visualize possible outcomes.
Anatomy of a decision tree
One of the nice things about a Decision Tree Diagram is that there aren’t a lot of elements. The key elements are called nodes, and appear as a square or circle with branches (lines) connecting them until a result is reached. Squares represent decisions, while circles are for uncertain outcomes.
Nodes have a minimum of two branches extending from them. On each line write a possible solution and connect it to the next node. Continue to do this until you reach the end of possibilities and then draw a triangle, signifying the outcome.
Once you’ve got the basic layout of a decision tree complete, you can add values to each line to garner more intelligence. Here’s how to do it:
1. Look at each line and add an amount to each.
2. To analyze your options numerically, add an estimate for the probability of each outcome. Note: When adding percentages all the lines from a single node need to equal 100, if you’re using fractions they need to add up to 1.
3. Assign a possible amount to each triangle at the end of the branches.
4. Calculate the results by multiplying the result by the percentage probability for each end branch in that outcome and subtract the cost of that course of action. You’ll end up with an estimate of what that particular outcome could yield.
Here’s an example:
Note: If you have a large tree with many branches, calculate the numbers for each square or circle and record the results to get the value of that decision. Start on the right side of the tree and work towards the left.
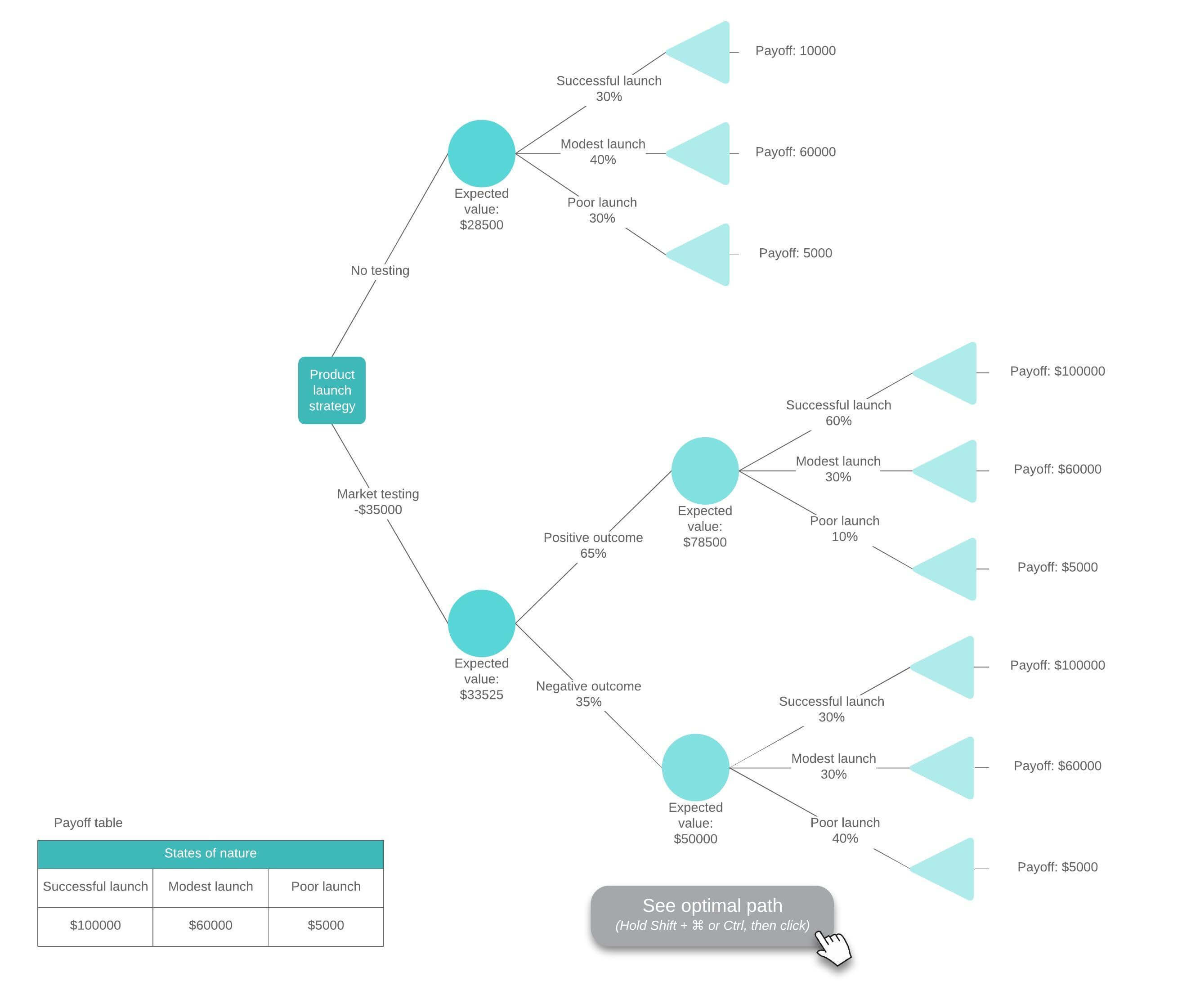
How to make a decision tree with Lucidchart
Let’s use Lucidchart to make a Decision Tree for a product launch, and decide if it makes sense to invest in market testing first. There are only a few symbols (circle, square, line, and triangle) in a Decision Tree Diagram, so we’ll make one from scratch. Log in to your account (if you don’t have one, sign up to try Lucidchart free for a week) and follow the steps below.
1. Open a blank document
In the Documents section, click the orange +Document button and double-click.

Tip: You can also click the orange down arrow and choose a blank diagram template. If you choose that option, skip to step 3.
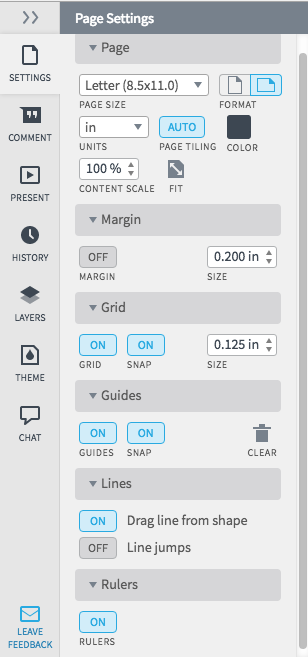
2. Adjust the page settings
When you open a blank document, instead of a template, you can change the page settings, margins, guides, grids, lines, rulers. On the right, you’ll notice the Page Settings menu where you can make any adjustments. Just click the options you want and once finished click the arrows next to Page Settings to hide the menu. Since Decision Trees can get large, we’re going to change the page format to landscape.
3. Name the decision tree diagram
Click on the Blank Diagram header at the top of the screen and type a name for the file.

Note: If you chose a template, a pop-up screen opens, type the name of your diagram in the text box and click OK. The new name appears in the top left corner of the screen.
4. Start drawing the decision tree
Click and hold the rectangle under Shapes and drag it to the far left side of your document. Decision trees are drawn left to right, so place it as close to the margin as you can. Use the grid and ruler to align the rectangle where you want it. Type the decision in the rectangle.
Tip: Use the text formatting options at the top of the diagram to change fonts, colors, spacing, etc.
5. Add nodes
Click and drag a circle to the diagram to add the uncertain nodes. Use the grids to align the circles on the page. To adjust the circle’s size, click on it, click on a blue square and drag it to resize. Type the name of the uncertain outcome in the circle.
You can add as many possibilities as you want, but you need a minimum of two options when starting a decision tree. Continue adding nodes to the decision tree until you reach the end outcome for each choice.
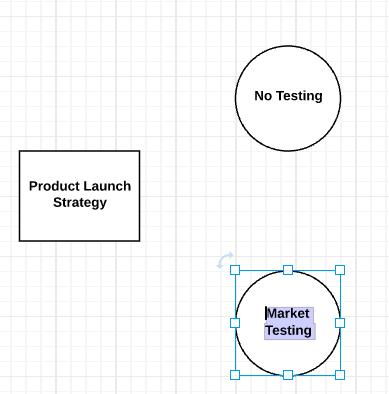
Tip: If you don’t want to resize each node (circle), simply click on an existing circle and press and hold Command+C on the keyboard. Next, press and hold click Command+V and a duplicate circle will appear, drag it into place.
6. Add branches to the decision tree
To draw lines between the nodes, click on a shape and click and hold one of the orange circles and drag the line to the next node. An arrow is automatically drawn between the two objects.
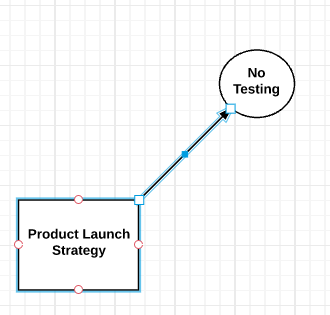
Tip: To remove the arrowhead from the line, choose No Tip from the Endpoint option for lines in the top menu bar.
When you get to the end of a branch, where no other decisions are needed in that route, add a triangle to the end of that row.
7. Add probabilities and values to the decision tree
It’s time to evaluate the decision tree, so you can estimate how much it’s worth if a particular outcome occurs. Look at the circles and add estimates for the probability of each outcome. To add numbers to the diagram, click on the large T in the Standard options and drag it to the spot where you want to add an estimate.
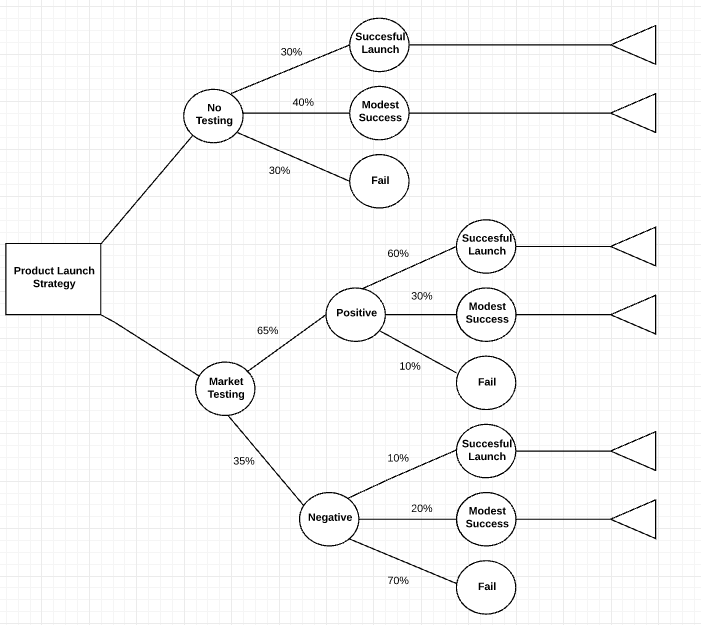
Note: Percentages for each node should equal 100, if you’re using fractions, each node should add up to 1. Feel free to use existing data, if you have it.
Next, add the cost of each option along the branch (decision line).
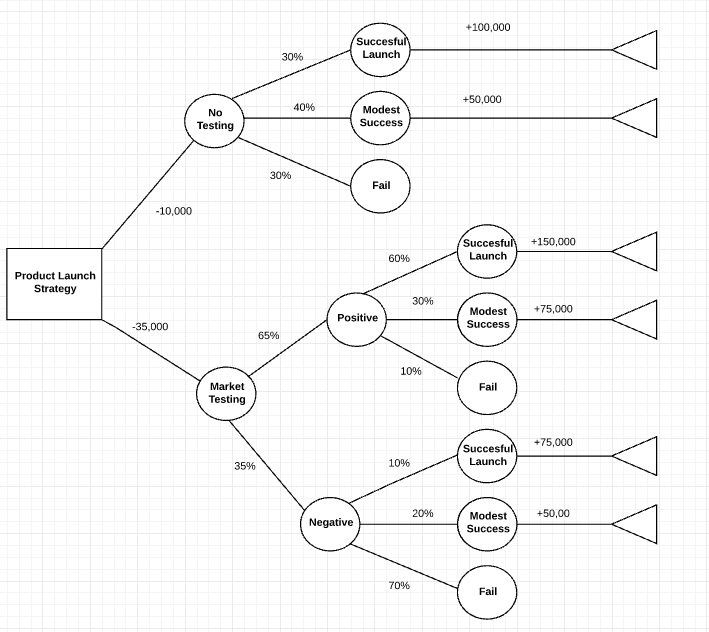
8. Calculate the value of each decision
Start on the right side of the tree and work towards the left. Subtract the cost each decision from the expected benefits.
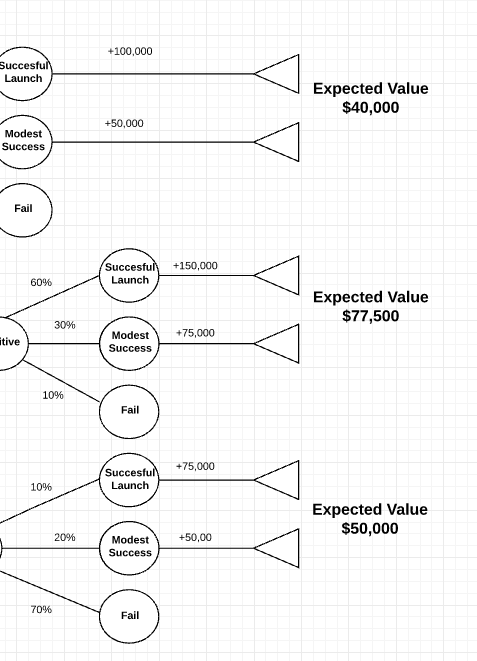
Once calculations are complete, you’ll clearly see which option will give you the biggest reward.
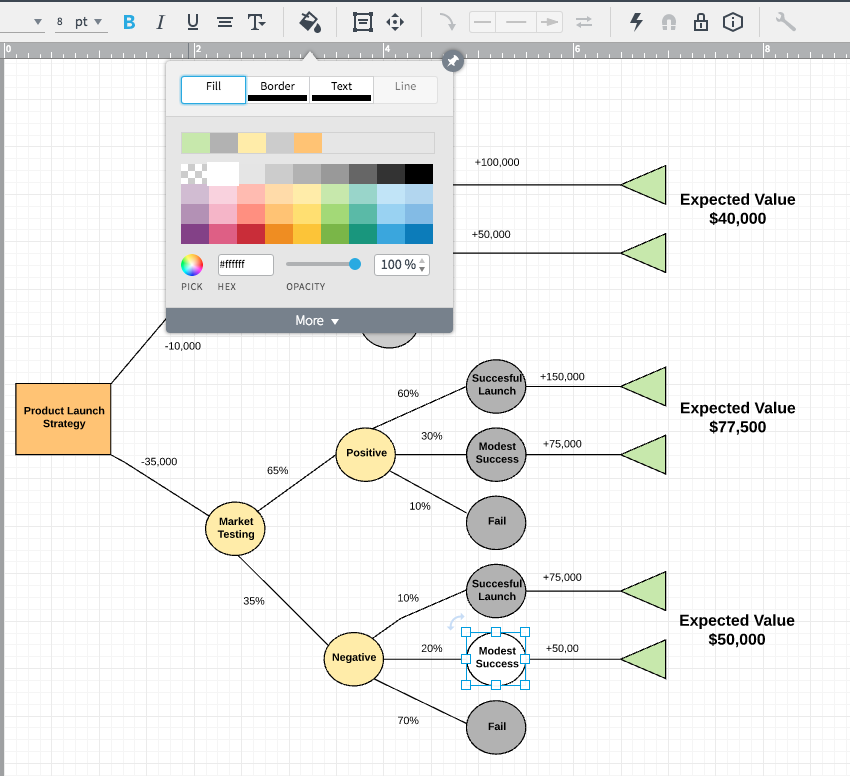
9. Add colors to the decision tree
Once you have the basic design of your decision tree complete, you can add colors by clicking on a symbol and then click the color-fill icon on the menu bar and choose a color.
10. Share your decision tree diagram
Once you like the way the decision tree looks, you can share it with others either via email, link, social media (Facebook, Twitter, Google+, and LinkedIn), or embed it on a website. Click the blue Share button in the top right corner of the screen and a pop-up will appear. Choose how you’d like to share the diagram and enter the appropriate information.
When you add a collaborator by sending a link to decision tree via email, you can work on the diagram simultaneously and use the chat feature to have discussions.