Types of database models
There are many kinds of data models. Some of the most common ones include:
- Hierarchical database model
- Relational model
- Network model
- Object-oriented database model
- Entity-relationship model
- Document model
- Entity-attribute-value model
- Star schema
- The object-relational model, which combines the two that make up its name
You may choose to describe a database with any one of these depending on several factors. The biggest factor is whether the database management system you are using supports a particular model. Most database management systems are built with a particular data model in mind and require their users to adopt that model, although some do support multiple models.
In addition, different models apply to different stages of the database design process. High-level conceptual data models are best for mapping out relationships between data in ways that people perceive that data. Record-based logical models, on the other hand, more closely reflect ways that the data is stored on the server.
Selecting a data model is also a matter of aligning your priorities for the database with the strengths of a particular model, whether those priorities include speed, cost reduction, usability, or something else.
Let’s take a closer look at some of the most common database models.
Master the basics of Lucidchart in 3 minutes
- Create your first diagram from a template or blank canvas or import a document.
- Add text, shapes, and lines to customize your diagram.
- Learn how to adjust styling and formatting.
- Locate what you need with Feature Find.
- Share your diagram with your team to start collaborating.
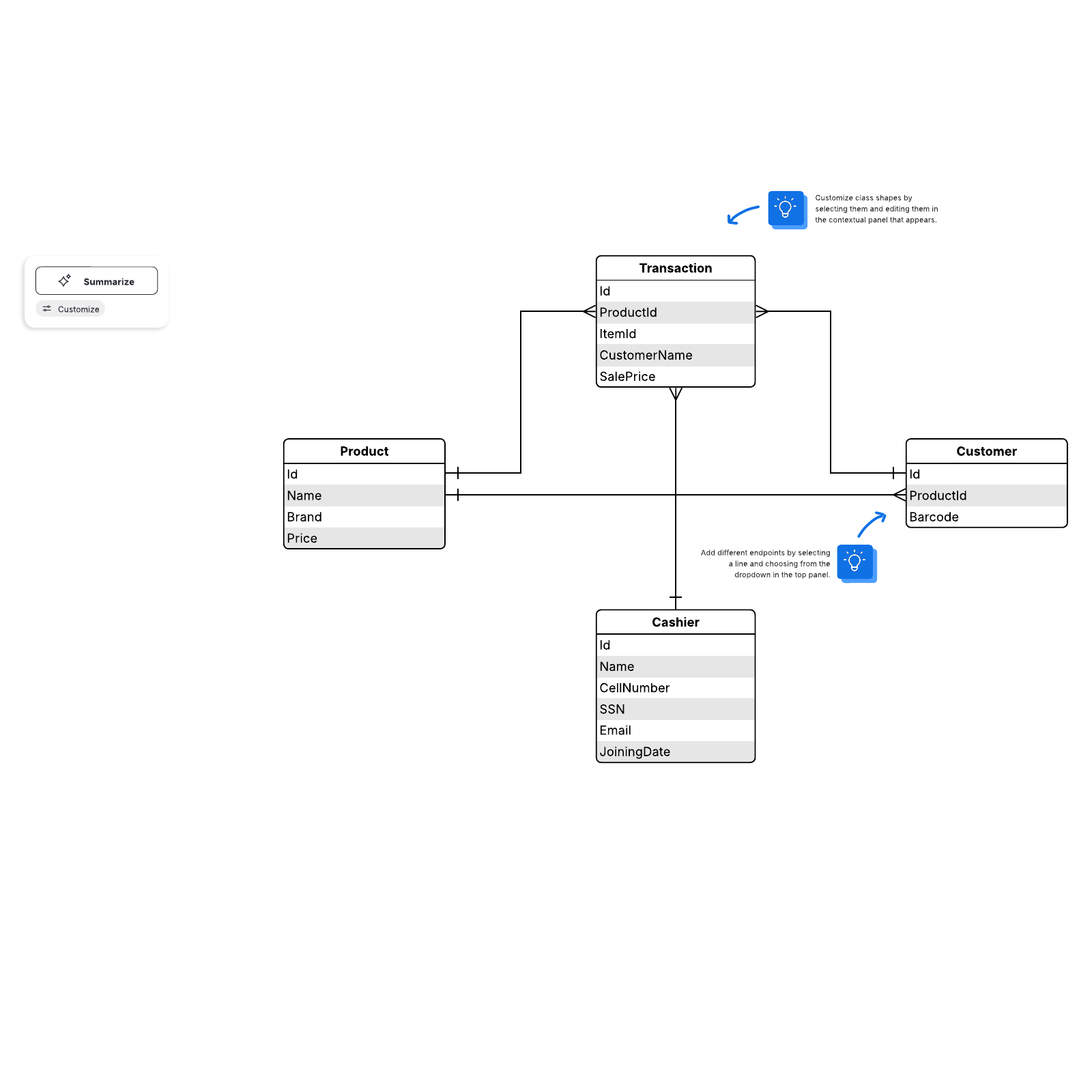
Relational model
The most common model, the relational model sorts data into tables, also known as relations, each of which consists of columns and rows. Each column lists an attribute of the entity in question, such as price, zip code, or birth date. Together, the attributes in a relation are called a domain. A particular attribute or combination of attributes is chosen as a primary key that can be referred to in other tables, when it’s called a foreign key.
Each row, also called a tuple, includes data about a specific instance of the entity in question, such as a particular employee.
The model also accounts for the types of relationships between those tables, including one-to-one, one-to-many, and many-to-many relationships. Here’s an example:

Within the database, tables can be normalized, or brought to comply with normalization rules that make the database flexible, adaptable, and scalable. When normalized, each piece of data is atomic, or broken into the smallest useful pieces.
Relational databases are typically written in Structured Query Language (SQL). The model was introduced by E.F. Codd in 1970.
Hierarchical model
The hierarchical model organizes data into a tree-like structure, where each record has a single parent or root. Sibling records are sorted in a particular order. That order is used as the physical order for storing the database. This model is good for describing many real-world relationships.

This model was primarily used by IBM’s Information Management Systems in the 60s and 70s, but they are rarely seen today due to certain operational inefficiencies.
Network model
The network model builds on the hierarchical model by allowing many-to-many relationships between linked records, implying multiple parent records. Based on mathematical set theory, the model is constructed with sets of related records. Each set consists of one owner or parent record and one or more member or child records. A record can be a member or child in multiple sets, allowing this model to convey complex relationships.
It was most popular in the 70s after it was formally defined by the Conference on Data Systems Languages (CODASYL).

Object-oriented database model
This model defines a database as a collection of objects, or reusable software elements, with associated features and methods. There are several kinds of object-oriented databases:
A multimedia database incorporates media, such as images, that could not be stored in a relational database.
A hypertext database allows any object to link to any other object. It’s useful for organizing lots of disparate data, but it’s not ideal for numerical analysis.
The object-oriented database model is the best known post-relational database model, since it incorporates tables, but isn’t limited to tables. Such models are also known as hybrid database models.

Object-relational model
This hybrid database model combines the simplicity of the relational model with some of the advanced functionality of the object-oriented database model. In essence, it allows designers to incorporate objects into the familiar table structure.
Languages and call interfaces include SQL3, vendor languages, ODBC, JDBC, and proprietary call interfaces that are extensions of the languages and interfaces used by the relational model.
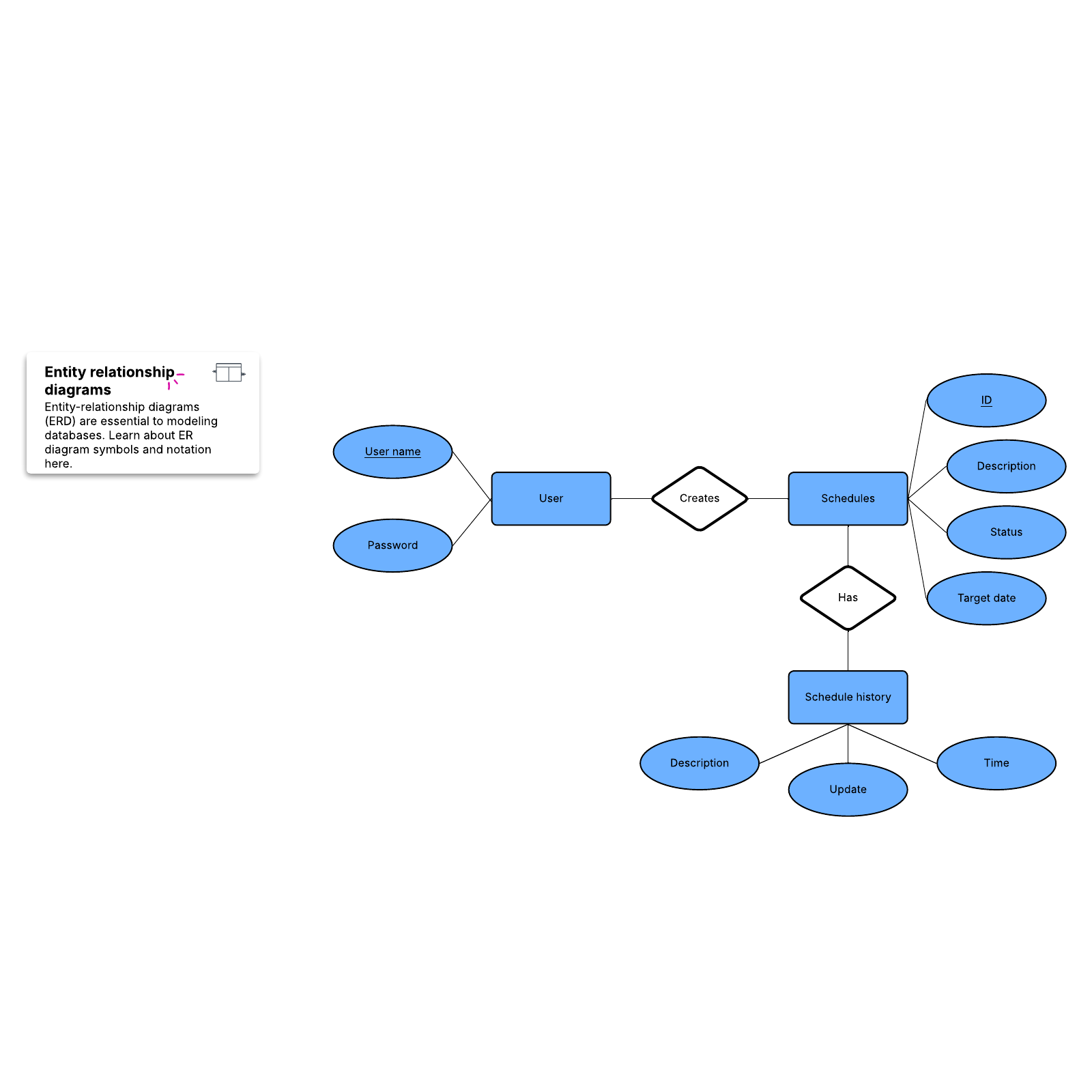
Entity-relationship model
This model captures the relationships between real-world entities much like the network model, but it isn’t as directly tied to the physical structure of the database. Instead, it’s often used for designing a database conceptually.
Here, the people, places, and things about which data points are stored are referred to as entities, each of which has certain attributes that together make up their domain. The cardinality, or relationships between entities, are mapped as well.

A common form of the ER diagram is the star schema, in which a central fact table connects to multiple dimensional tables.
Other database models
A variety of other database models have been or are still used today.
Inverted file model
A database built with the inverted file structure is designed to facilitate fast full text searches. In this model, data content is indexed as a series of keys in a lookup table, with the values pointing to the location of the associated files. This structure can provide nearly instantaneous reporting in big data and analytics, for instance.
This model has been used by the ADABAS database management system of Software AG since 1970, and it is still supported today.
Flat model
The flat model is the earliest, simplest data model. It simply lists all the data in a single table, consisting of columns and rows. In order to access or manipulate the data, the computer has to read the entire flat file into memory, which makes this model inefficient for all but the smallest data sets.
Multidimensional model
This is a variation of the relational model designed to facilitate improved analytical processing. While the relational model is optimized for online transaction processing (OLTP), this model is designed for online analytical processing (OLAP).
Each cell in a dimensional database contains data about the dimensions tracked by the database. Visually, it’s like a collection of cubes, rather than two-dimensional tables.
Semistructured model
In this model, the structural data usually contained in the database schema is embedded with the data itself. Here the distinction between data and schema is vague at best. This model is useful for describing systems, such as certain Web-based data sources, which we treat as databases but cannot constrain with a schema. It’s also useful for describing interactions between databases that don’t adhere to the same schema.
Context model
This model can incorporate elements from other database models as needed. It cobbles together elements from object-oriented, semistructured, and network models.
Associative model
This model divides all the data points based on whether they describe an entity or an association. In this model, an entity is anything that exists independently, whereas an association is something that only exists in relation to something else.
The associative model structures the data into two sets:
- A set of items, each with a unique identifier, a name, and a type
- A set of links, each with a unique identifier and the unique identifiers of a source, verb, and target. The stored fact has to do with the source, and each of the three identifiers may refer either to a link or an item.
Other, less common database models include:
- Semantic model, which includes information about how the stored data relates to the real world
- XML database, which allows data to be specified and even stored in XML format
- Named graph
- Triplestore
NoSQL database models
In addition to the object database model, other non-SQL models have emerged in contrast to the relational model:
The graph database model, which is even more flexible than a network model, allowing any node to connect with any other.
The multivalue model, which breaks from the relational model by allowing attributes to contain a list of data rather than a single data point.
The document model, which is designed for storing and managing documents or semi-structured data, rather than atomic data.
Databases on the Web
Most websites rely on some kind of database to organize and present data to users. Whenever someone uses the search functions on these sites, their search terms are converted into queries for a database server to process. Typically, middleware connects the web server with the database.
The broad presence of databases allows them to be used in almost any field, from online shopping to micro-targeting a voter segment as part of a political campaign. Various industries have developed their own norms for database design, from air transport to vehicle manufacturing.