How to Implement a Successful ITIL Incident Management Process
Lucid Content
Reading time: about 7 min
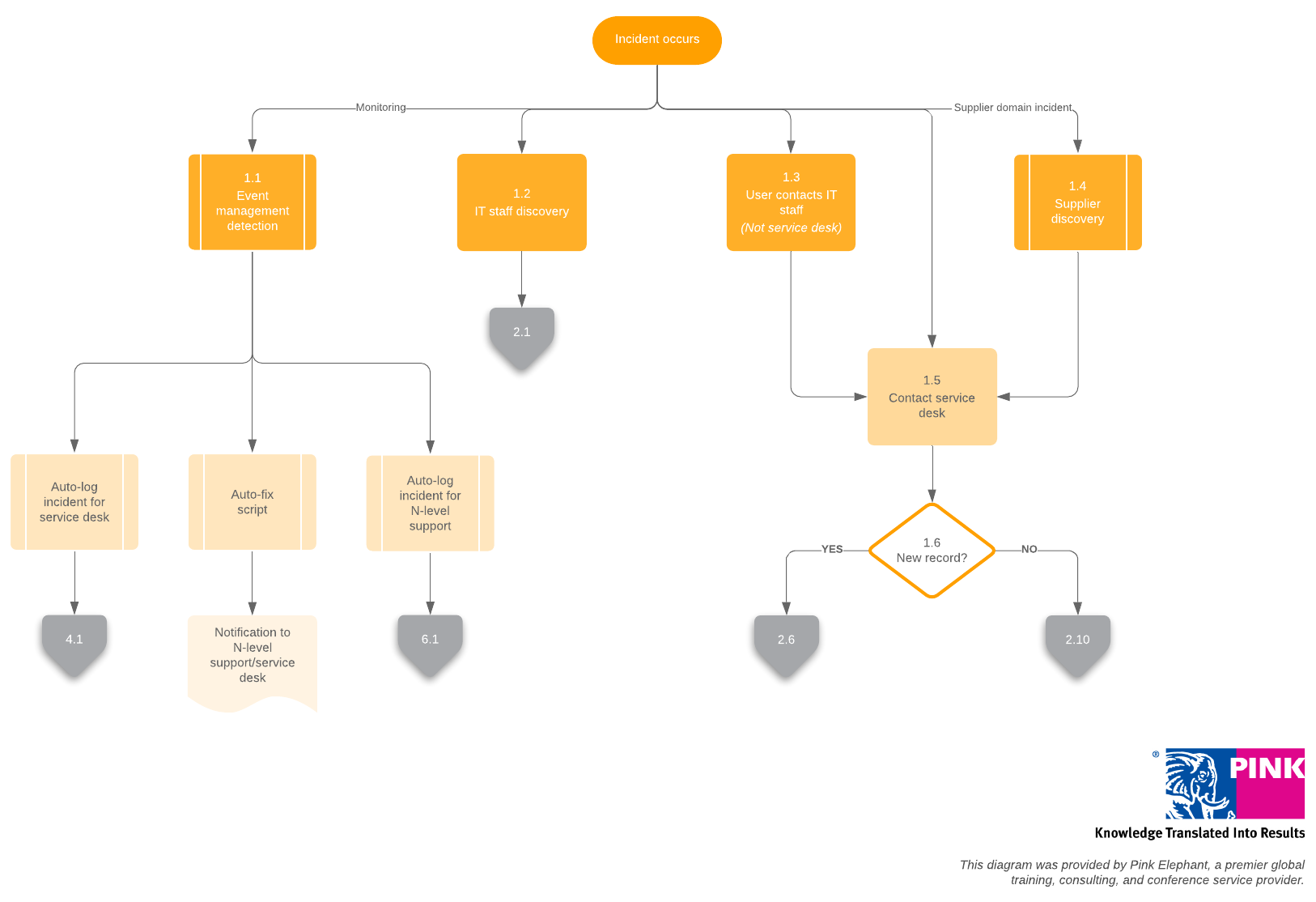
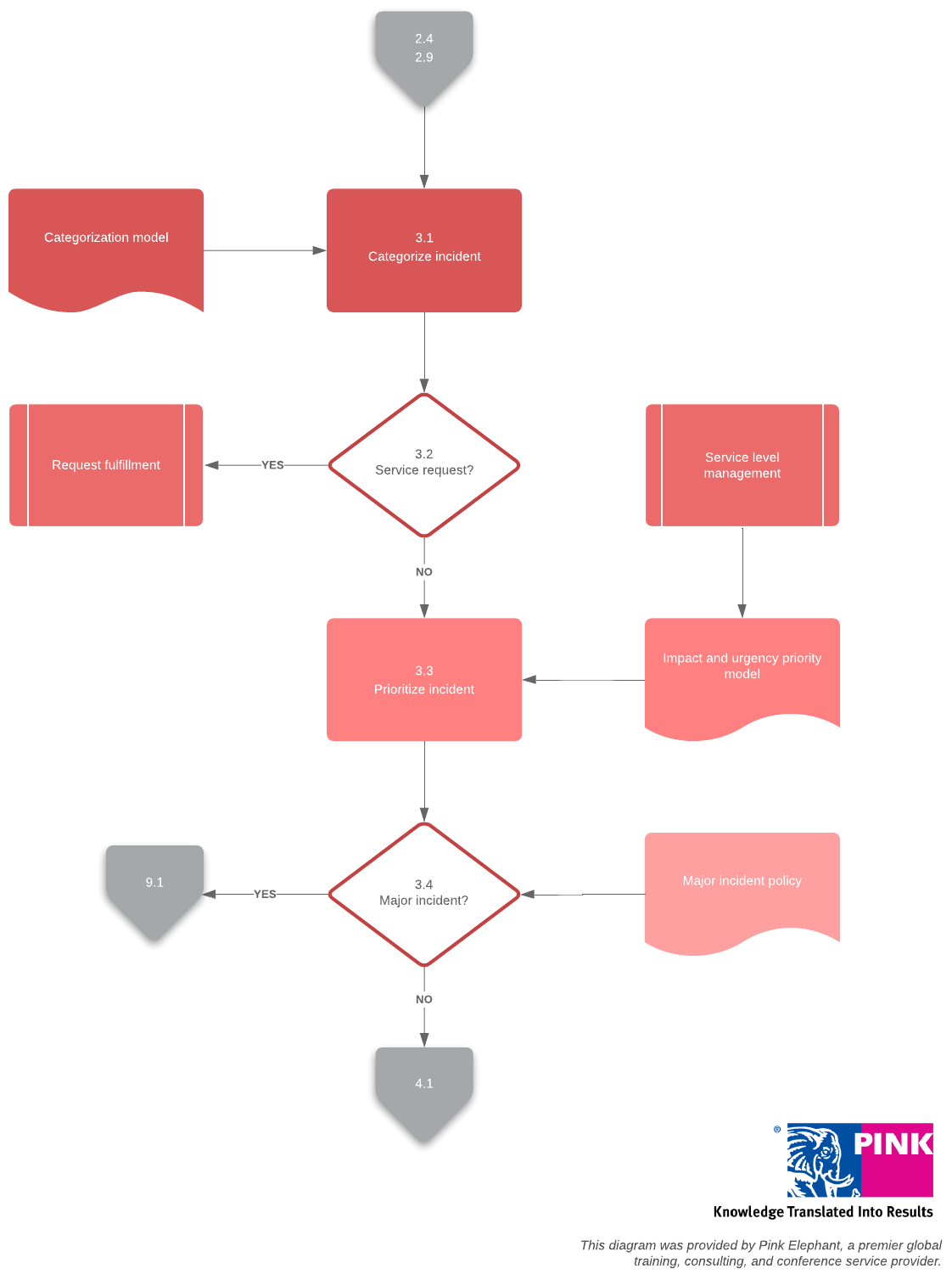
Additionally, by recording detailed information surrounding each incident, you can create better models and categories to organize your incident data.
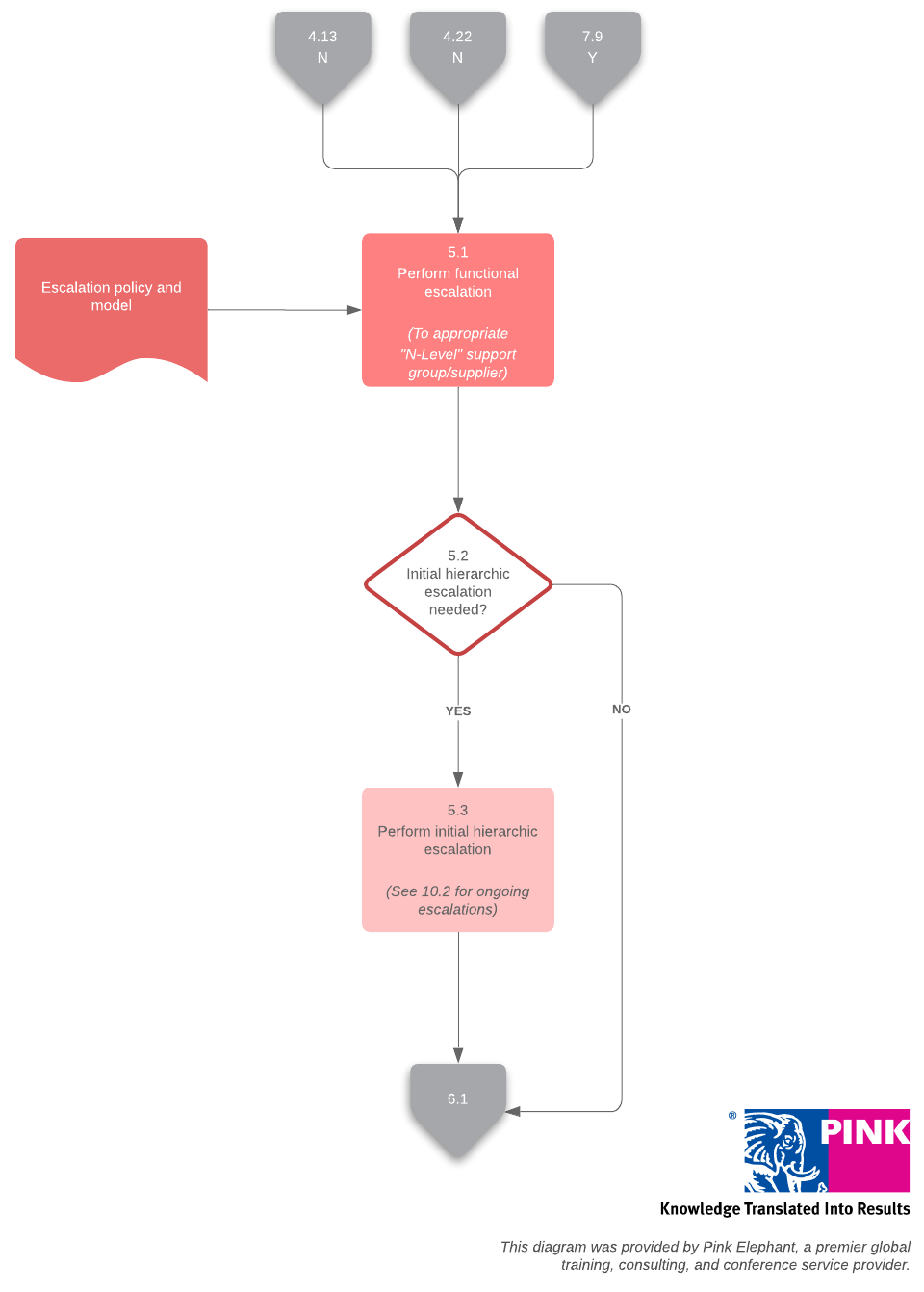
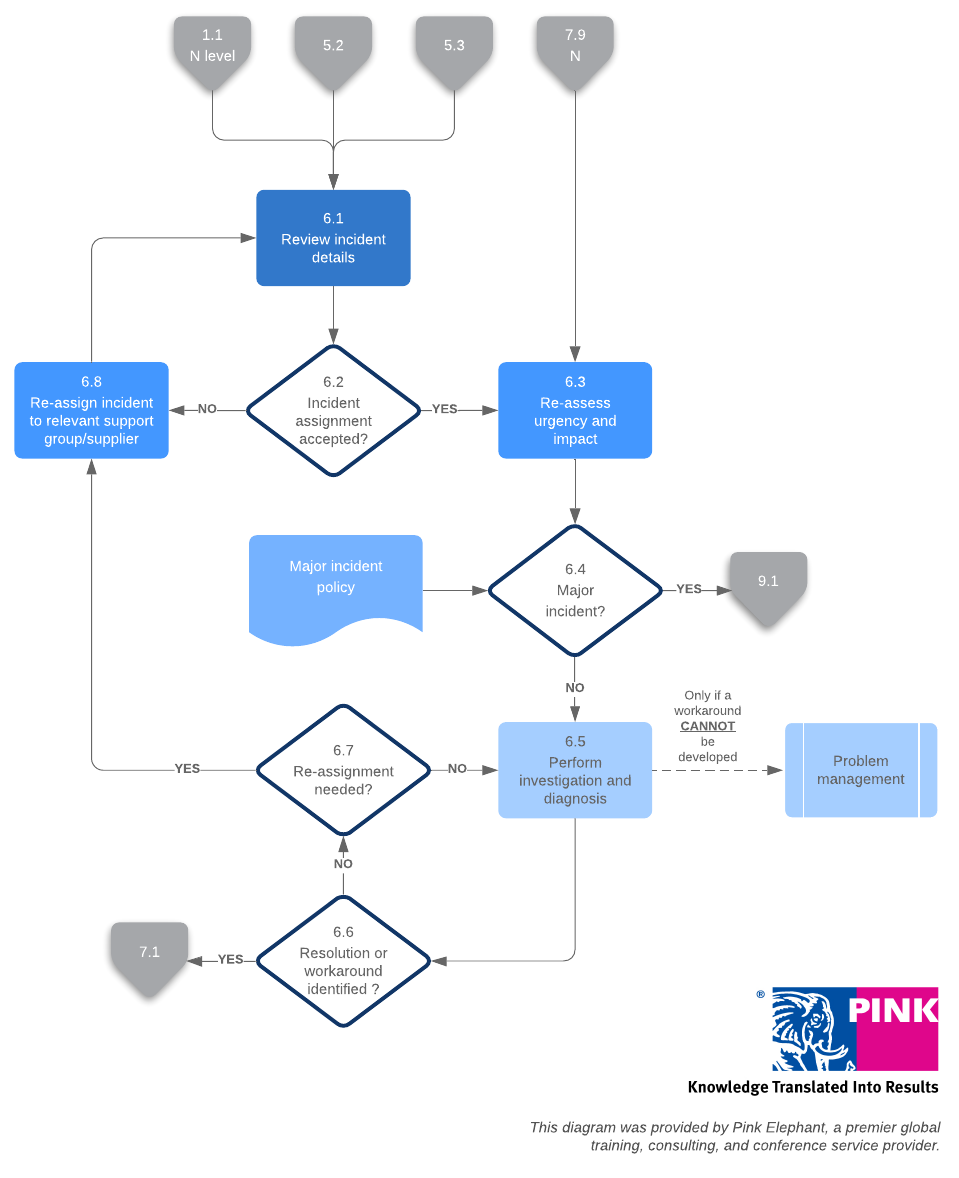
7. Resolution and recovery
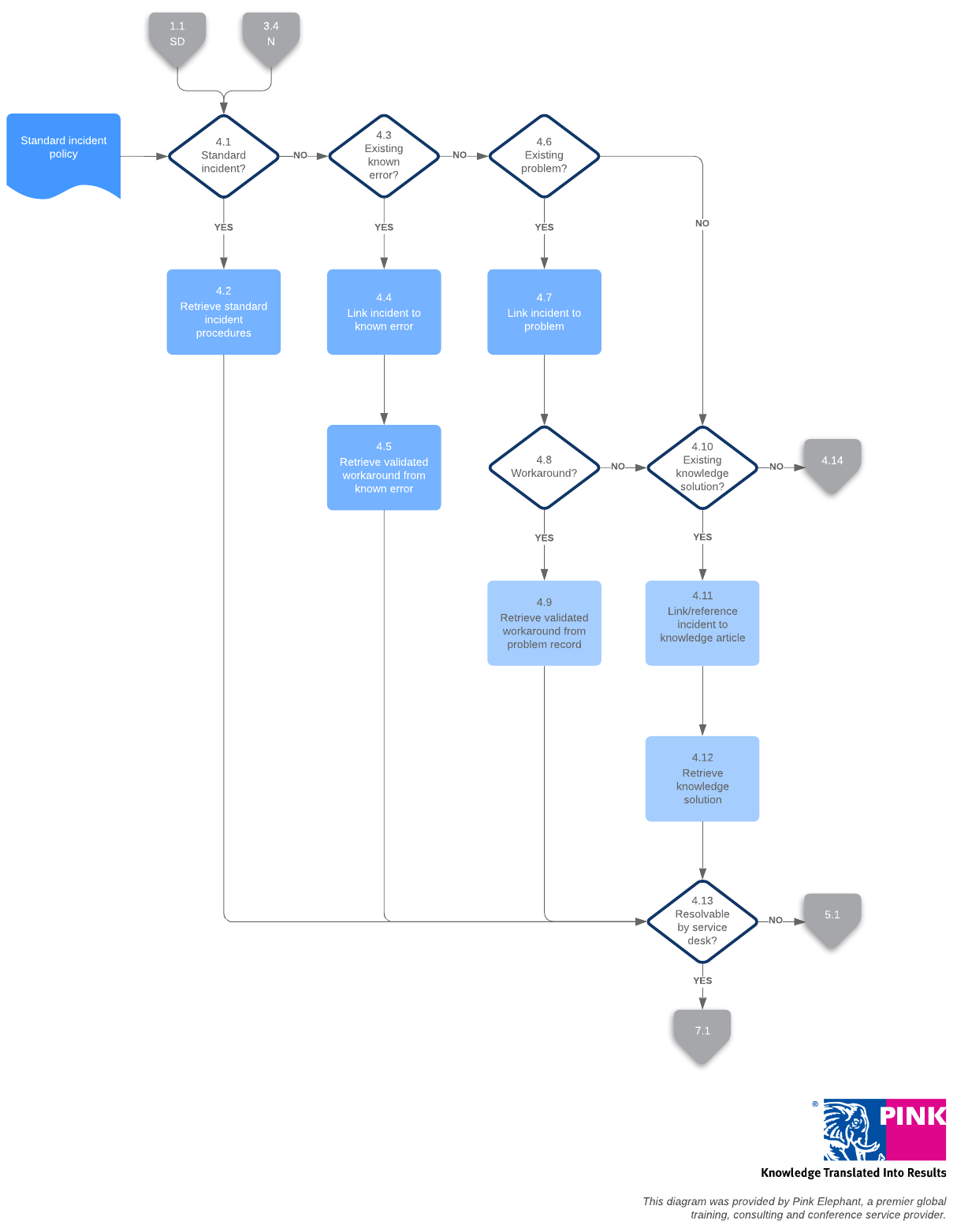
Once the team has nailed down the correct diagnosis, they can get to work fixing the issue. In this stage, the service desk will confirm the service has been properly restored.
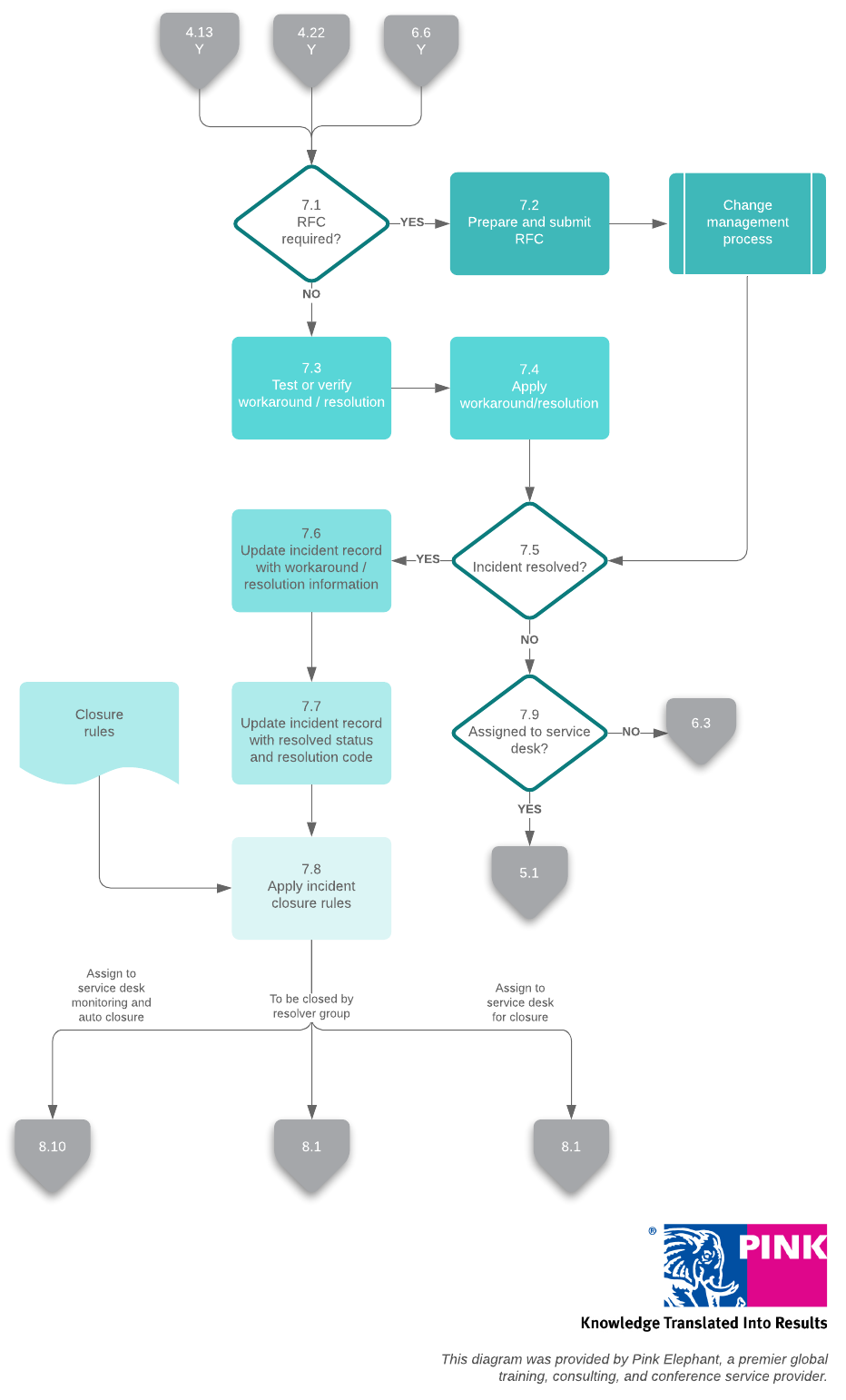
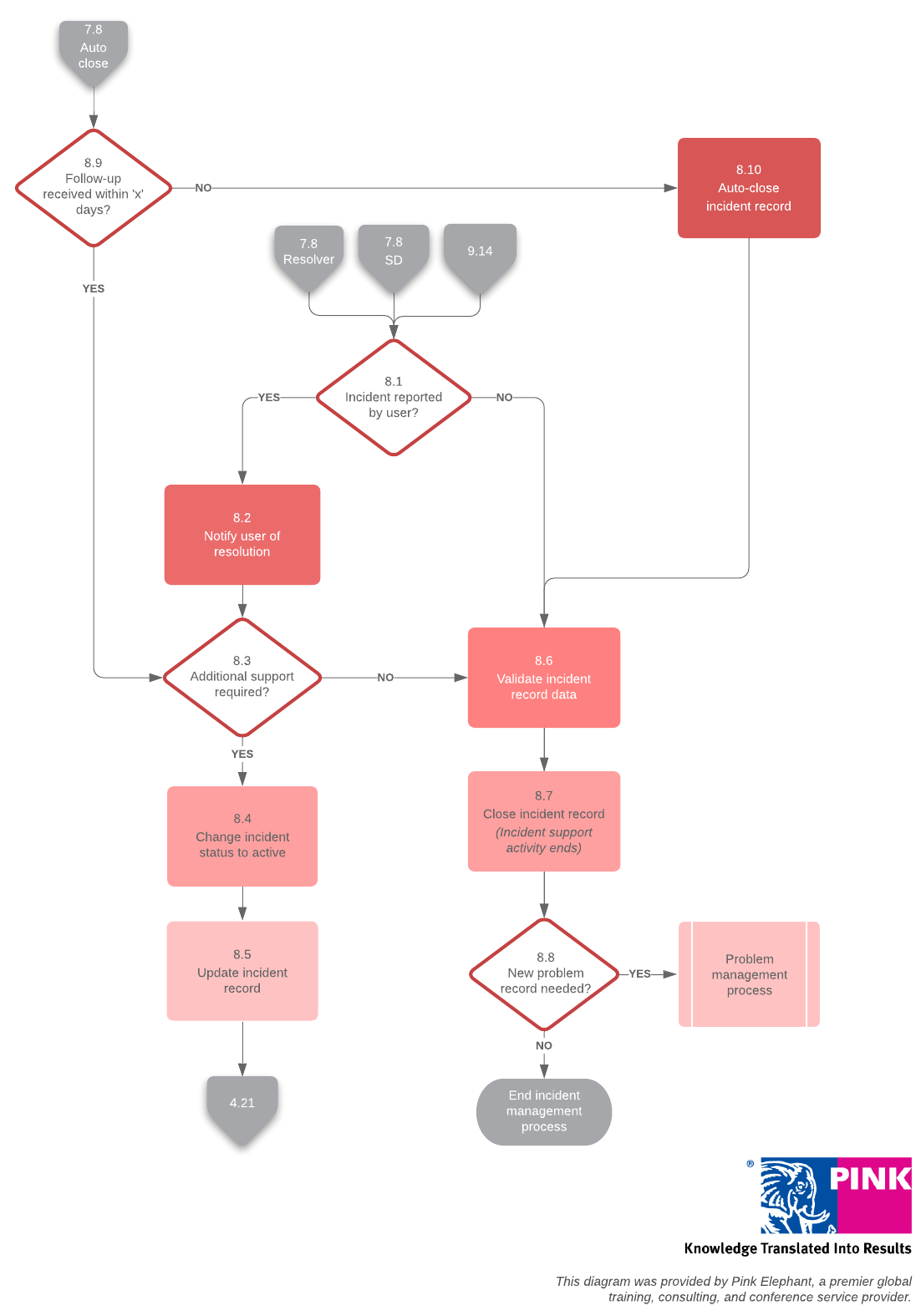
8. Incident closure
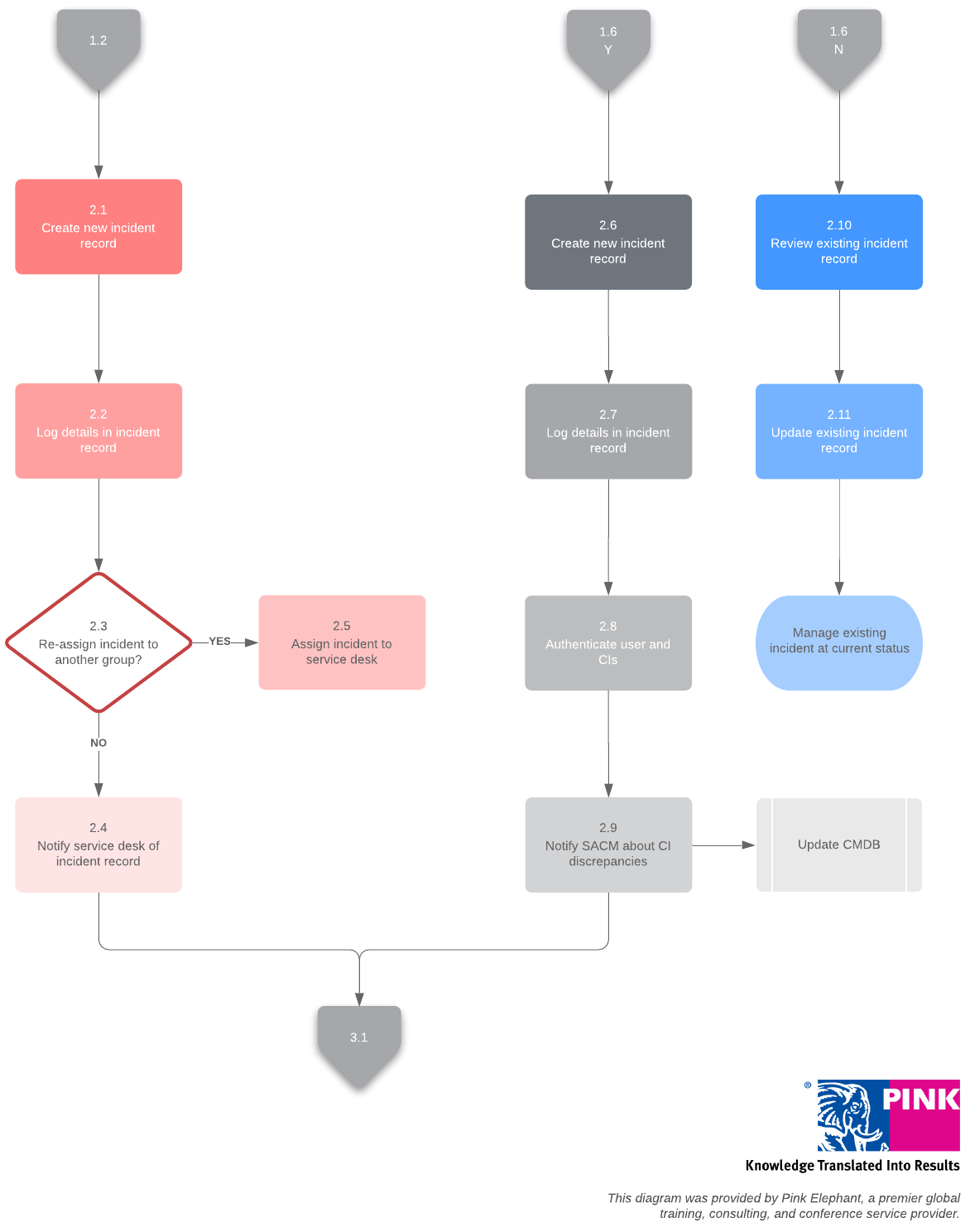
When the incident is resolved, the service desk confirms the fix and closes the ticket. Be sure to confirm with the user who originally reported the incident that the service has been fully restored before closing the ticket.
About Lucidchart
Lucidchart, a cloud-based intelligent diagramming application, is a core component of Lucid Software's Visual Collaboration Suite. This intuitive, cloud-based solution empowers teams to collaborate in real-time to build flowcharts, mockups, UML diagrams, customer journey maps, and more. Lucidchart propels teams forward to build the future faster. Lucid is proud to serve top businesses around the world, including customers such as Google, GE, and NBC Universal, and 99% of the Fortune 500. Lucid partners with industry leaders, including Google, Atlassian, and Microsoft. Since its founding, Lucid has received numerous awards for its products, business, and workplace culture. For more information, visit lucidchart.com.
Related articles
How to Track AWS Status With Lucidchart
Millions of companies run their applications through AWS, but you need to remain vigilant and monitor AWS status in case the service experiences downtime or your application doesn't perform as well as it should. Learn how to create an AWS status dashboard.
Improving your organization’s web security testing
High-profile data breaches in the last few years have put data security at the forefront of political, tech, and business news. Learn what security testing is and how you can implement better testing processes to protect your organization and your users.
4 common IT problems that Lucidchart solves
In this article, we’ll explore four common problems IT professionals face and how to mitigate them using Lucid.
5 tips for clearly mapping incident management flows for IT teams
This article will share tips and templates for IT teams to confidently map their incident management process.
Bring your bright ideas to life.



By registering, you agree to our Terms of Service and you acknowledge that you have read and understand our Privacy Policy.